

 DALLE Generated Image — “Google Android Logo but in a 3d artistic style”
DALLE Generated Image — “Google Android Logo but in a 3d artistic style”
This article is a step-by-step guide on how we can setup a GitHub Actions Workflow to leverage OpenAI’s Text Completion API to automate adding string translations for an Android App.
TLDR: This is the GitHub repo of an Android project leveraging OpenAI’s Text Completion API to add Polish, Ukrainian, and British English translations whenever a American English string is added to
main/res/values/strings.xml
The Backstory
I came across a Slack message one day at work about a button that was breaking layouts for some of our Polish users. I noticed, using my elementary-school level knowledge of the language (sorry Mom & Dad), that the intended translation was way more complicated than it needed to be. Simple solution you might think, lets just change this one instance and problem fixed! No so much.. and so I start asking myself some questions:
- What about the hundreds of the other strings?
- What about the two dozen or so other languages?
- Who vets these translations on our end?
- What does this cost the company?
There are almost 5 thousand strings that exist today, and thats only a snap-shot of all translations that have existed up to this point. I focused back in on the issue and went to Google Translate. Sure enough, it gave me that shorter translation I expected. I then put my engineering cap on, what if … we can use an API to do this for us instead of a Translation Service?
Enter ChatGPT 👋
All this talk about ChatGPT3 was top of mind, even my non-tech-savvy sister (love u sis ❤) sent me text a week ago asking if I’ve heard of it, to which I replied snarkily “Yes, its all the rage”. I went over to the OpenAI website to have a chat with our AI overlords and input a simple phrase:
> Translate "Lorem Ipsum Dolor Sit Amet" to Polish < █ "Twoja mama chce wiedzieć, dlaczego nie jesteś lepszy z polskiego" // Translation: Your mom wants to know why your not better at Polish
Eureka! ChatGPT is being powered by my own Mother! Just kidding, though it did output the proper translation for the actual phrase I gave it. If we take a look the documentation (which is fantastic) we can see a ton of in-depth information around the theory of Text Completion. That will then link us to some API docs which show some basic curl commands. Furthermore, they give us a fancy Playground web app which lets us experiment.

What are we building?
Let’s first start by defining an objective: What are we trying to accomplish? If we can get a simple ask then we can start picking it apart for more details. I’ve used my own proprietary ChatGPT3 clone, WallyGPT25™ for help.
 WallyGPT25™ In action to help us figure out what we need to build! This is also completely fake.
WallyGPT25™ In action to help us figure out what we need to build! This is also completely fake.
See, WallyGPT25™ is so much better than ChatGPT3 and what a detailed request I was able to make! Oh.. but it looks like I’m out of WallyTokens™, guess I need to continue on with ChatGPT3 for the rest of this blog post. Lets get started then!
On to the rough approach
For this blog post, we’ll make a very basic Android application. It’ll be a single module application which means there will be a single res/values directory, for now. However, that doesn’t mean we should ignore some small things which will let our code scale easier in the future:
- Once our app reaches “critical mass” in size (i.e. 15 minute builds ugh) then we’ll start to break apart our single Gradle module project into a multi-module project. This means multiple
res/values/strings.xmlfiles that’ll exist. - We have the option of overriding classes / assets per Gradle variant or flavor which brings another source of
res/values/strings.xmlfiles. donottranslate.xmlare sources of strings, that (you may have guessed) should not be translated, so we want to make sure we key off the file namestrings.xml- We want to respect the
translatableattribute for a string defined in astrings.xmlfile and avoid translations for those as well (e.g. yourapp-name). - We want the translations to grow and shrink to the size of the source
values/strings.xmlfile. If a feature gets removed then the translation strings for the feature should also!
Our project will be hosted on GitHub, and we can use Github Actions as our CI because its free. We like free. Our CI is whats going to do all the heavy lifting here, so we want to also use a language thats easy to understand and for that I choose you Python.
 DALLE Generated Image — “Ash Ketchum throwing a Poké Ball at a Pokémon but instead of a Pokémon its the Python logo”
DALLE Generated Image — “Ash Ketchum throwing a Poké Ball at a Pokémon but instead of a Pokémon its the Python logo”
Jobs
Our CI workflow needs to do the following:
1. Only run this CI job when there is a new commit pushed to our main branch
on:
# Triggers the workflow on push for the "main" branch
push:
branches: [ "main" ]
2. Clone the repo using a GitHub Personal Access Token that has read and write permissions and stored via Github Secrets.
- uses: actions/checkout@v3
with:
token: ${{ secrets.GH_PAT }}
3. Setup the Python environment
- name: Set up python environment
uses: actions/setup-python@v2
with:
python-version: 3.11
4. Install any extra python dependencies we might need. In our case we use requests for easy HTTP calls to the OpenAI API.
- name: Install python dependencies
run: |
python -m pip install requests
5. Run the translations script which adds/modifies our strings.xml files. We also need to pass in the environment variable OPENAI_API_KEY, with a value stored in Github Secrets. This allows us to reference it in our python script via a os.environ.get() call. Pro tip, not hardcoding API tokens will make your security team sleep well at night.
- name: Run translations script
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
run: python ${GITHUB_WORKSPACE}/.github/scripts/translations.py
shell: sh
6. Commit any new/modified strings.xml files to the repo. We can use a pre-made step which will automatically commit files that match the defined file_pattern . Pro tip, only use steps that have been assessed and approved by your security team, this will also makes them sleep well.
- uses: stefanzweifel/git-auto-commit-action@v4
with:
commit_message: Adds Translations
commit_user_name: "Translations[Bot]"
commit_author: Translations Bot <w@dziemia.com>
file_pattern: '*/strings.xml'
The Script
For now, we will hardcode the array of languages within the script itself. This will be a simple key-value map of android resource-qualifiers to the name of the language the qualifier represents. The key will be used to append to new folders that need to be created. The value will be used in the prompt we send to OpenAI.
qualifier_language = {
"pl": "Polish",
"en-rGB": "British English",
"uk": "Ukrainian",
}
We then need to search through the repo for all paths that match **/src/*/res/values/strings.xml. The values/strings.xml file acts as our source file within however many Gradle modules exist. We’ll supply translations for every instance of the file which will allow this script to scale from one Gradle module to many over time.
source_paths = pathlib.Path(GITHUB_WORKSPACE).glob('**/src/*/res/values/strings.xml')
And so for each path in source_paths, we iterate through all the strings to get a set of source_strings. Each of those strings should be translated in the languages defined in qualifier_language.
source_strings = dict()
for source_path in source_paths:
source_tree = ET.parse(source_path)
for child in source_tree.getroot():
# Respect translatable attribute
if child.attrib.get(XML_ATTR_TRANSLATABLE) == "false":
continue
# Add this child to our dict where key is the name attribute
source_strings[child.attrib.get(XML_ATTR_NAME)] = child
And now we can use the qualifier_language map which lists the language we want to translate and check if the qualified values directory (e.g. values-pl/) exists along with strings.xml
res_directory = source_path.parent.parent
for qualifier in qualifier_language.keys():
qualified_values_folder_name = 'values-{qualifier}'.format(qualifier=qualifier)
qualified_values_folder_path = os.path.join(res_directory, qualified_values_folder_name)
qualified_values_folder_exists = os.path.exists(qualified_values_folder_path)
qualified_strings_file_path = os.path.join(qualified_values_folder_path, "strings.xml")
qualified_strings_file_exists = os.path.exists(qualified_strings_file_path)p
We then keep track of the qualified translations that need to be added or removed. We pre-populate the qualified_strings_needed dictionary with source_strings and then remove the ones we come across if the qualified translations file exists. If it doesn’t then we create a new qualified strings file (and folder if needed) and proceed on!
qualified_strings_remove = list()
qualified_strings_needed = dict()
qualified_strings_needed.update(source_strings)
if qualified_strings_file_exists:
strings_tree = ET.parse(qualified_strings_file_path)
for qualified_string in strings_tree.getroot():
# Let's ignore the strings that are marked with translatable=false
if qualified_string.attrib.get(XML_ATTR_TRANSLATABLE) == "false":
print("Ignoring: " + qualified_string.attrib.get(XML_ATTR_NAME))
continue
# Now we check to see if this qualified file has the translation
qualified_string_key = qualified_string.attrib.get(XML_ATTR_NAME)
if qualified_string_key in qualified_strings_needed:
# If it does, remove it from the ones we need
qualified_strings_needed.pop(qualified_string_key)
else:
# If it doesn't, then the source-strings.xml is not in-sync with the qualfied-strings.xml, so we
# let's keep track of that and remove the translation.
qualified_strings_remove.append(qualified_string_key)
else:
# Create the dir if needed
if not qualified_values_folder_exists:
os.mkdir(qualified_values_folder_path, 0o777)
new_strings_file = open(qualified_strings_file_path, 'w')
new_strings_file.write("<resources></resources>")
new_strings_file.close()
We’re now able to make an API call to OpenAI with the translations that we need via qualified_strings_needed. First we need a prompt, and this is where it gets tricky. We want the API to return something formatted so that we can do less work. I found that this is where it gets difficult and how you phrase your prompt matters.
prompt = "Translate each of these phrases, excluding punctuation unless present, into " + \
qualifier_language[qualifier]
for qualified_string_needed_key in qualified_strings_needed:
prompt += "\n" + qualified_strings_needed[qualified_string_needed_key].text
# Which will end up as:
#
# Translate each of these phrases, excluding punctuation unless present, into Polish
# Hello World
As for the API request, using text-davinci-003 model will give us the best result and is recommended for this use case as it can understand a complex level of instructions. If we send a request to translate Hello World then we should see a response like the following:
{
"id": "cmpl-6gcJAOM0RDFzlQpL09ALHo1dA387l",
"object": "text_completion",
"created": 1675615052,
"model": "text-davinci-003",
"choices": [
{
"text": "\n\nCześć Świecie",
"index": 0,
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 8,
"completion_tokens": 13,
"total_tokens": 21
}
}
And now here comes the fun bit about unstructured data. We see that the API might return \n\n at the start of the string. If we are sending multiple phrases to translate then any additional phrase will be delimited by \n . We need to replace \n\n with any empty string and then we can split this string by \n as the delimiter. This should work but having a structured data response would bring me more joy.
I need to trust the API to return 3 translations for 3 phrases and so we need to make sure that’s the case. If it doesn’t then we need to get out of town .. and proceed onto the next language.
if len(filtered_response_strings) != len(qualified_strings_needed):
print(
"...Stopping translations for {qualifier}, OpenAI response returned {oai_count} item(s) but we "
"expected {local_count}".format(
qualifier=qualifier,
oai_count=len(filtered_response_strings),
local_count=len(qualified_strings_needed)
))
continue
From there, it’s just a matter of taking our phrases and adding them to the XML file. We should also remove any strings that are no longer part of our source strings.xml file. I will not bore you with those details but do want to make a note that the order that we’ve placed the phrases in the prompt matters. When inserting these new translations to our XML files, we need to iterate over qualified_strings_needed in the same order because we do not want to accidentally mismatch translations.
The Final Product
 Log of the Job that ran on GitHub Actions
Log of the Job that ran on GitHub Actions
Once we’ve pushed everything up to GitHub, we can see our script ran with some nice logging which says that we’ve added three translations. This job was spun up when we made a change to strings.xml (PR #1) and merged those changes in to the main branch.
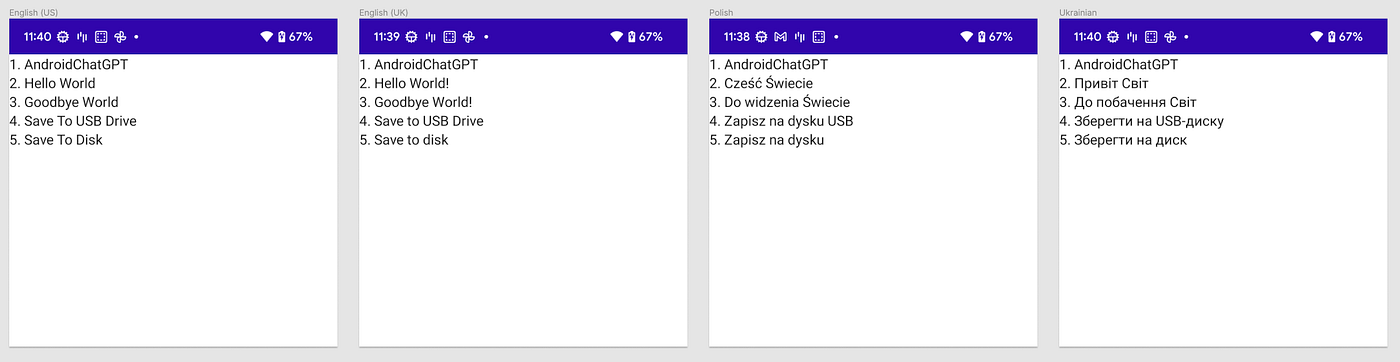
 The new strings that were added to each qualfied strings.xml file
The new strings that were added to each qualfied strings.xml file
The workflow used OpenAI API to fetch our translations and modified the strings.xml files that were associated with the qualifier_language map in translations.py. When we pull the latest from main and build our app we see:
And we can now say that we fulfilled what our AI overlord had asked of us! Hooray!

And now we must part ways
Thanks for coming along on this journey!
So, you might be wondering if you should use this in Prod and … If you were to ask me then I’d say Nope … I wrote this script in a day and there are more optimizations we can make. For example, the job runs on every new commit that hits main .. which you’d want to adjust the workflow to only run on commits which only contains changed files that match **/src/*/res/values/strings.xml for their path.
There are still many open questions by going with this approach. The language model may work for these languages I used, but what about less common languages? What happens when we pass up a string with formatting arguments or special characters? This is not to say that OpenAI isn’t a powerful tool but the inputs needed and output it generates still requires a lot of “jiggling of the handle”.
I’ve tried to optimize each prompt to be as simple as possible in order to make parsing easier but it still causes me some difficulty. The returned response is not structured data (e.g. JSON) and so you need to work around that. If you ask, within the prompt, to JSONify the response .. well then you have JSON within JSON without your \ chars being double escaped .. causing you to try XML and immediately regretting it.
Its still cool though.
Thank you to Ramona Harrison and Sameer More for you help!
Happy Coding!
W
This article was originally published on proandroiddev.com







