

Photo by Josue Isai Ramos Figueroa
Here’s a scenario that’s recognisable to most Android developers… You are tasked with adding a simple feature to an app, but doing so forces a change in another area, and then another and another, until the footprint of your change becomes so unwieldy it’s impossible to test.
You’ve probably also worked on apps where making a change in a hacky way is significantly easier than figuring out how to do something properly. Or apps where a change in one part of the app causes hundreds of totally unrelated bugs to pop out of the woodwork.
These are all the hallmarks of bad architecture.
So this article — based on my talk Don’t Fight The Architecture — is about how to architect your app well.
The right way to do it
Because when you architect your app well, you will find it’s secure, reliable, testable and maintainable. You will be able to delay decisions like which back end to use, and reverse such decisions later down the line with relative ease. And most importantly for us developers, there’s a clear “right way” of doing things, which correctly isolates pieces that need isolation, meaning even the most junior of developers can be useful in the team.
There’s a lot of advice out there about the “right” way to architect software. A lot of it conflicts. So what I’m going to do in this article is give you the principles behind architecture so you can make your own mind up about what’s appropriate for your own app. So this article is about principles, not rules.
To be a good architect, learn the principles not the rules. That way you can tailor an architecture to what is right for your software and team.
SOLID Rules
The SOLID rules underpin many architectural frameworks, and are therefore essential to understand fully. I’m not going to go into them in too much depth, because others have done a good job of it. However, to review them briefly:
S = Separation of Responsibility
This is the principle that a class or module should only have one reason to change. Or equivalently, it should only ever be responsible to one actor. This essentially means: segregate things that will evolve separately.
O = Open-Closed
Your code should allow you to add new features by adding code, not by modifying existing code.
L = Liskov Substitution
Named for Barbara Liskov, computer scientist at MIT. This principle states that you should be able to use any derived class in place of the base class. Most importantly, you shouldn’t try to change the meaning of the base class in your derivation of it.
I = Interface Segregation
Clients shouldn’t be forced to use an interface which isn’t appropriate to them. There’s no harm in having lots of small one-or-two method interfaces instead of one big one.
D = Dependency Inversion
High level classes shouldn’t depend on low level classes. Instead they should both depend on abstraction.
Correct application of the dependency inversion principle leads to the correct formation of architectural boundaries. Let’s look in more depth at how that works.
Architectural boundaries and dependency inversion
Let’s say we have an app that allows people to create and save their profiles. We use Firebase to do so. Here’s a naive implementation of that:

WRONG: Breaking the dependency inversion principle
Here the User class calls a method in FirebaseProfileSaver which saves the profile using Firebase. The User class is said to be high-level because it contains business logic (i.e. it’s pure logic rather than about specifics of how data is read and written to the system). And by contrast, FirebaseProfileSaver is a low-level class, so-called because it contains implementation specifics, i.e. code written for a particular technology.
This layout breaks the dependency inversion principle because something high-level is dependent on something low level. When I say dependent on, I mean in a strict source code sense: the User class has a line which says import x.y.FirebaseProfileSaver or equivalent. Perhaps the dependency is a couple of layers removed — say User imports X which imports Y which imports FirebaseProfileSaver — but the point is you can draw a set of arrows in the direction of dependencies which eventually point from User to FirebaseProfileSaver.
Why is this a problem? Well, one issue is that Firebase changes aren’t isolated. If the Firebase SDK changes one day, then obviously FirebaseProfileSaver will need to change; but there’s nothing to stop that from happening in a way that affects User and anything else dependent on it. Testing the change will mean testing everything.
And it’s not very flexible, either. If we want to move from Firebase to some other remote storage provider, we might end up having to rewrite large parts of the app.
Dependency inversion: the “plug socket” solution
The solution is for FirebaseProfileSaver to be a kind of “plug” and for the User class to be a kind of “socket”. The User class must know nothing of FirebaseProfileSaver; but it’s allowed to know about saving profiles in the abstract. Regardless of what “plug” we put into the User’s “socket” (it could be a FirebaseProfileSaver or a RoomDatabaseProfileSaver or MyProprietaryAPIProfileSaver), the “socket” knows how to talk to it, because from its perspective they all operate the same.
So FirebaseProfileSaver is refactored into a plug that fits the socket.
It looks like this:
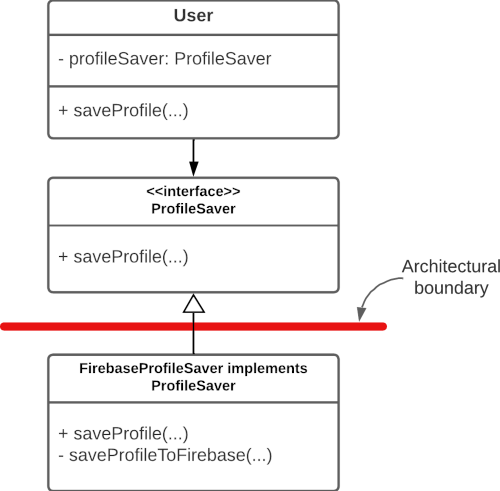
Here, the User class only knows how to talk to a “ProfileSaver” in the abstract. Importantly, it contains no mention of anything to do with Firebase.
Then, a FirebaseProfileSaver implements the ProfileSaver interface. The User class has no knowledge of this and so, crucially, does not base any of its logic on how Firebase works.
This isolates the Firebase logic. We can draw a red line like in the diagram above between low-level code and high-level code. This red line is an architectural boundary.
Notice how the dependency arrow now points upwards from the low level to the high level. There is no longer any sequence of dependency arrows you could follow that start at the User class and end up at Firebase.
Where should architectural boundaries go?
So clearly the correct placement of architectural boundaries is essential to good architecture. From the above, it might look like the more boundaries the better — but that’s not true.
Architectural boundaries have a maintenance overhead. They produce more code, and once a boundary is in place every future developer has to respect it.
And the code with the boundary is much less readable. It’s not obvious from the above that the User class’ profileSaver.saveProfile() call actually triggers Firebase logic. And so, onboarding new developers is made that little bit trickier and code reviews are slightly harder.
One attempt at rationalising where architectural boundaries go is Clean Architecture.
How about Clean Architecture for Android apps?
A set of principles collated by veteran architect Robert C Martin, Clean Architecture in part offers a way of rationalising software into a select set of layers, divided by architectural boundaries.
Its famous diagram looks like this:
The famous Clean Architecture diagram, from Robert C Martin’s book “Clean Architecture”
OUR VIDEO RECOMMENDATION




Jobs
This layered diagram has the high-level code (that is, pure logic) in the center and low-level code on the outside. It is governed by the Dependency Rule (essentially a result of SOLID’s Dependency Inversion principle), which states that low-level code may depend on higher level code, but never the other way around. Hence the arrows in the above, which represent dependencies, always point inwards.
So what do these layers consist of?
Use cases and entities (yellow and red circles)
Right in the centre of the Clean Architecture diagram we find the Use Cases and Entities layers. These contain your app’s business logic. That’s the pure logic governing the behaviour of the app, with nothing to do with implementation specifics.
That distinction can be confusing, so here’s an example.
A use case that saves a user’s profile does the following:
- Run some security / consistency checks. Make sure that the profile being saved contains valid data and that the user is going to be allowed to perform this operation.
- Save the data remotely
- Cache the new profile locally
- Inform the UI that it needs to update
You can tell that this is all business logic because it’s about what we’re doing, not how we’re doing it. At step 2, for example, we don’t say what remote API we’re using to save the data, and at step 4 we don’t care if the UI to update is a screen on an Android phone or a web page or a PDF.
A use case represents a single requirement from a single actor (refer to SOLID’s Single Responsibility principle above). It’s also a comprehensive list of steps — there’s nothing more that you need to do in order to save the profile, and there’s no sense in ever attempting to run only a subset of those steps.
Interface adapters (green circle)
This is where the specifics of the use cases go. When a use case asks to cache some data locally, for example, this is where we are allowed to talk about SQL databases. We still don’t talk about a particular brand of SQL database — anything that’s a proprietary technology comes later. If there are multiple sources of data then the interface adapters layer should collate them and manage discrepancies.
This is also where almost your entire MVVM, MVC, MVP, etc. topology should go. Again no proprietary tech — so we don’t talk about Jetpack Compose or Android XMLs here — but we do hold the state that those parts will use.
Frameworks and drivers (blue circle)
This is where anything that uses proprietary technology goes. These are the implementation details.
Here’s where your Jetpack Compose @Composable s go. Here’s where your HTML goes. And Firebase code, the specifics of any API, and SQL commands, and anything marked with a Room annotation (e.g. @Entity)…
Code in this layer is hard to test because it typically relies on the proprietary technology to do so. Jetpack Compose testing, for example, relies on tools written specifically for Jetpack Compose (or perhaps those written for Android in general, but the point remains). So, keep this layer as thin as possible. Logic should go in higher layers. This is just the bare minimum needed to “translate” requirements of the interface adapters to the particular technology you’re using.
This layer is also volatile. It can change and break without your input. For example, if an API you’re using suddenly requires a different kind of authentication, you will have to alter your code to match, regardless of whether the timing suits you or whether you’re happy with the change. Again, keeping this layer as thin as possible reduces the impact of such changes across the rest of the codebase.
Where does Android-specific code sit in Clean Architecture?
Officially according to Clean Architecture, Android is a proprietary technology and so it should be restricted to the frameworks and drivers (blue) layer. Nothing with “import android.x.y” or “import androidx.x.y” should go beyond this layer.
This can be very difficult to achieve in practice.
One example is permissions requesting which is sometimes more convenient (and readable) to mention in the view model, i.e. the interface adapters area.
So this is a perfect example of why I wanted this article to be about principles not rules. If you’re bending over backwards to fit a rule, then consider the principles behind it — they may or may not be relevant in your case.
For this example, I personally consider it OK to take the decision to allow Android to be mentioned in the interface adapters. After all, you’re building an Android app and unless there’s some reasonable likelihood that you’ll one day sharing the precise same codebase with say an iOS or web app, there’s no value in contorting your code into not mentioning Android. Obviously iOS and web apps usually have their own, separate, codebases.
What makes a good app, and how can we architect that?
An app should do one thing and do it well. Its purpose doesn’t change much over time, and though it may well evolve many new features in its life, its target audience almost never changes (it has the same actor as per the Single Responsibility principle). In fact, if a stakeholder starts requesting that your app caters to an additional kind of user, you are often better off creating a new app for them so that it can properly focus on their needs. Microsoft doesn’t have a single Office app; instead it has separate Word, Excel and Powerpoint apps, each used by different people with different requirements.
So you might well say that Clean Architecture — many of the principles of which are designed to insulate you against these kind of changes which aren’t likely to occur in an Android app — is simply too heavy for our purposes. In many cases I would agree with you.
Google seems to agree, too. Its own architecture recommendations — which it calls Modern App Architecture — is a somewhat softer version of Clean Architecture.
Google’s Modern App Architecture
Google simplifies its architecture into three layers:
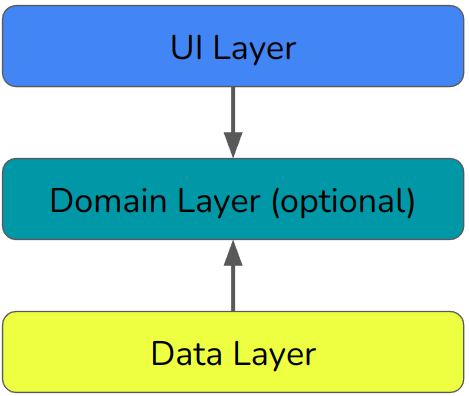
Topology of Google’s Modern App Architecture
Broadly speaking, the UI layer is for handling input and output from the users, and updating the display. The domain layer is for your business logic — almost exactly equivalent to Clean Architecture’s use cases. And the data layer is for reading and writing data to the app’s storage mechanisms.
This is a unidirectional architecture. State only flows up, events only flow down.
Let’s look at what all that means in more detail.
The UI layer: UI elements and state holders
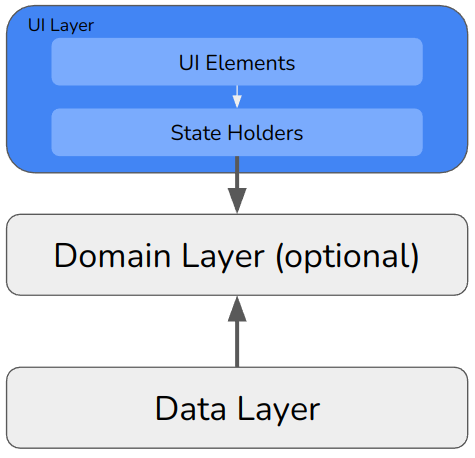
Modern App Architecture’s UI layer
The UI layer is split into UI elements and state holders.
The UI elements part exclusively contains code written for proprietary technologies. If you’re using Jetpack Compose, then place your @Composables here. If you’re using Fragments and XML then this is where that goes. But nothing else. No logic, and no data.
(The ‘no logic’ rule is sometimes difficult for users of XML data binding. For example data binding would allow you to implement a Celcuis/Fahrenheit switch entirely inside the XML code. Don’t.)
The logic and data, by contrast, goes into the state holders. They are so-called because they hold the state of the UI. Think view controllers. They contain the variables which back your UI controls — so if, say, your UI has a text field then the variable that contains the content of that text field goes here.
An excellent recommendation is to expose such state variables as Kotlin Flows. This neatly encapsulates their dynamic nature, and provides an in-built mechanism for signalling to the UI that it needs to update.
The domain layer: use cases
The domain layer contains use cases, which are precisely the same as the use cases in Clean Architecture. That is, a comprehensive list of steps needed to perform a single task, by a single actor.
But in Google’s architecture, this layer is optional. That means there’s nothing wrong with placing pure business logic in the state holders (view models, say) instead.
Where business logic is reused across multiple state holders, it can be useful to pull that logic out into the domain layer to prevent code duplication. Say for example multiple parts of the app allow the user’s profile to be updated; in that case, you can create an UpdateUserProfileUseCase and reference it wherever needed.
The data layer: repositories and data sources
The data layer is split into repositories and data sources.
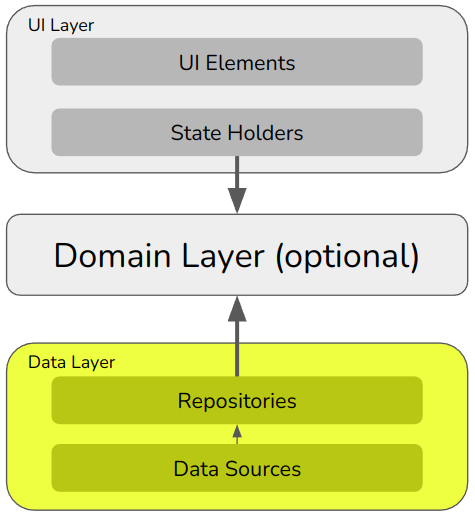
Modern App Architecure’s data layer
The repository is responsible for providing data and saving data. It will contain, say, getUserProfile() and saveUserProfile(…) methods.
The data source does the proprietary work, say by calling an API or writing SQL commands.
Often a repository is responsible for multiple data sources. For example, you might have data stored in a remote repository and a local cache of the same. Each one of those would be implemented as a separate data source. Then when reading a user’s profile, the repository might attempt to read from the local cache and fall back to the remote database if the cache is empty. In this way, a repository responsible for multiple data sources has to orchestrate which one to use, and how to synchronise them.
Again it is good practice to make data available to callers using Kotlin Flows.
Comparing Google’s Modern App Architecture to Clean Architecture
You may have noticed that Modern App Architecture and Clean Architecture each use the word “layer” to mean a subtly different thing. Here’s how they fit together:
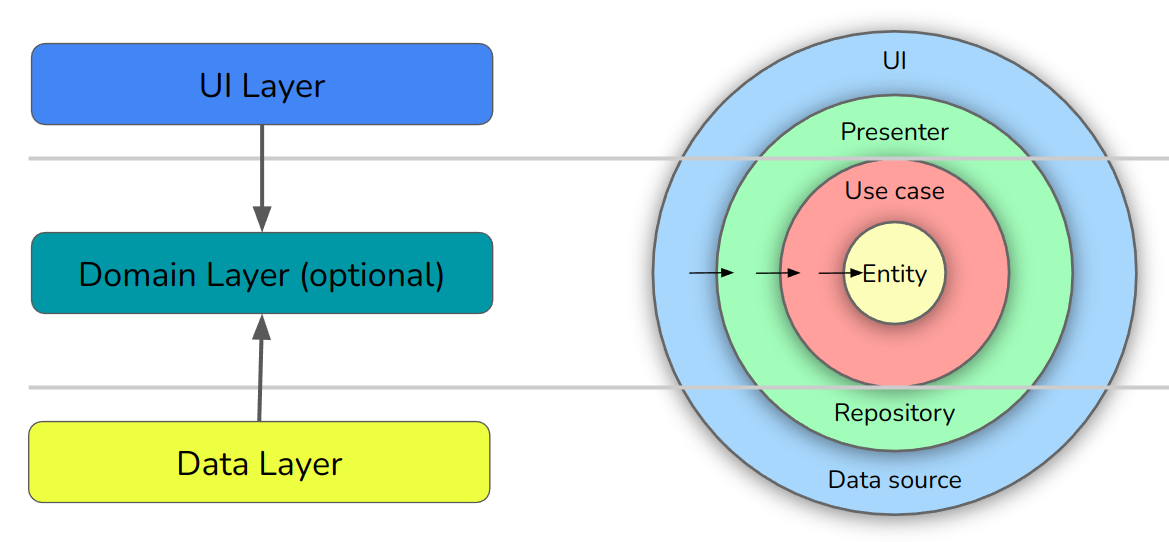
How Modern App Architecture fits with Clean Architecture
Google’s UI layer, like its data layer, fits across the outer two rings of Clean Architecture (interface adapters and frameworks and drivers). Its domain layer is entirely equivalent to Clean Architecture’s use cases and entities.
Some of these boundaries are slightly more blurred than the diagram above shows. For example, Google has nothing against you placing business logic in the UI layer, which is why its own domain layer is marked as optional.
The UI and Data Layers are both equivalent to Clean Architecture’s Interface Adapters and Frameworks / Drivers layers.
To conclude…
This has been a deep dive into the principles behind good architecture, using for inspiration two common paradigms: Clean Architecture, and Google’s Modern App Architecture.
It’s of course up to you to figure out what works best for your application. I hope that in providing the thoughts rather than rigid frameworks, I’ve given you a toolkit to make your own decisions.
I like answering specific questions about architecture, so feel free to leave responses here and I’ll respond when I can. It’s most fun when there isn’t a single ‘right’ answer and we get to have a discussion.
In a future article I’ll be using the above to take you step-by-step through creating a well-architected sample app in Kotlin and Compose.
Tom Colvin has been architecting software for two decades. He’s co-founder of Apptaura, the mobile app specialists, and available on a freelance basis.
This article was previously published on proandroiddev.com







