

I implemented the same functionality using both frameworks to compare them side by side. Which one would I choose on a real-world project?
GPUs have become one of the most sought-after resources given the latest explosion of AI. Prices of GPUs have skyrocketed, and Cloud providers have embarked on a sort of ‘20th Century Space Race’ to be the ones offering the best infrastructure to run AI models.
But what if I told you that you currently possess a powerful GPU device that you use daily? It’s essentially free to use, and it’s either in your hand or in your pocket right now.

All modern mobile phones come with an integrated GPU that could be used for on-device machine learning inference. They are not going to perform like a ~USD 1500 NVIDIA RTX 3090 GPU, but depending on your use case, they can be adapted to get the job done.
Why would you want to use your phone instead of a powerful GPU for machine learning inference?
Security
Any form of communication with an external Server will require that your data be transported via some sort of external channel. There are methods to secure the channel, but nothing will beat on-device processing. By using on-device inference, data never leaves your device.
Speed
A Cloud GPU will be a lot faster to perform inference, but you still need to transmit the data over the internet, with all of what that implies. Transit speed will be impacted by the speed of your phone network or Wi-Fi connection. Think about the use case where you need to enhance a photo using AI tools. You’ll need to serialize the image on the phone first. Then send it to your back-end server using HTTP or similar. The Cloud server will need to run the AI model on the image, and then return the serialized edited image. Finally, the phone needs to deserialize it and render. It’s a massive overhead, and we haven’t even started the discussions on encryption and security in transit.
Cost
Running on Cloud requires that you purchase your own GPU and connect it to a server, or use any of the AI Solutions that AWS, Azure, Google Cloud, or other providers offer. Any of these will have a variable cost once your user base starts to grow.
Running inference on-device is practically free, as you are directly leveraging the user’s phone computing power.
Offline mode
On-device inference allows you to run even when you don’t have any kind of network connection since all of the processing happens directly on the device.
Hopefully, by now, I’ve convinced you that we should give on-device machine learning a shot.
The main drawback is of course the performance and computing power.
GPUs were built specifically for running operations on Tensors. You can’t expect to achieve the same results from your ‘all in one’ everyday phone, but there are techniques that will allow you to run smaller, fine-tuned models where the loss in performance shouldn’t be significant.
Enough with the intro, let’s get our hands dirty!
What did I do?
I tried out the 2 most significant frameworks for on-device machine learning, TensorFlow Lite and PyTorch Mobile.
I created an Object Detection app and implemented the same functionality with both frameworks, inspired by the demo apps they provide in their official documentation.
The app opens the camera and starts feeding the captured images to either TFLite or PyTorch Mobile, depending on our selection. The framework runs the model on the image and responds with a set of bounding boxes and labels depicting the objects found in the image.
https://miro.medium.com/v2/resize:fit:750/format:webp/1*SnX2HNGgFd58pjThfAfxFw.gif
Object detection in action: Laptop, couch, and Ronnie.
For the UI I used Compose, Coroutines/Flows for passing data between layers, Hilt for Dependency Injection, and MVVM for the presentation layer architecture, something like this:
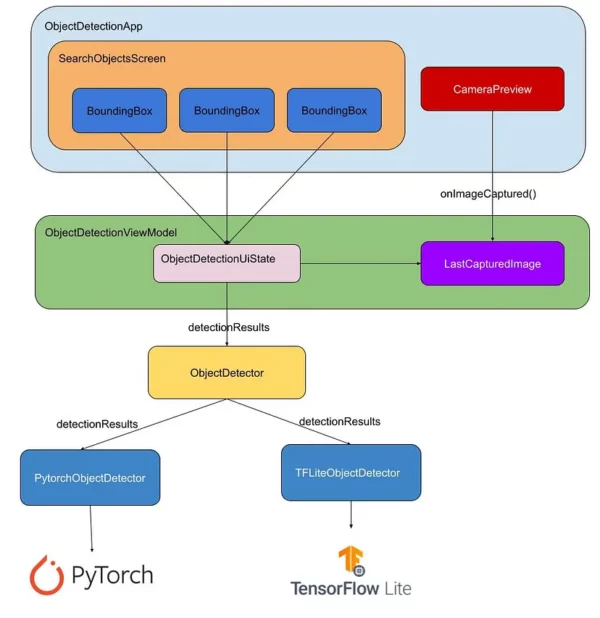
Comparison

Jobs
I am a developer, and as such, I will be focusing on the items that developers suffer the most. Ease of implementation, size, support, and reliability. I won’t be diving deep into complex benchmarks to compare performance over multiple inference situations as it is not my area of expertise. So let’s get started…
- Ease of implementation and APIs
This is a critical point for any developer. We want something that we can add to our project and start using right away without too much configuration and hassle.
Both libraries can be included in your project as a normal Gradle dependency. They both have their core versions and more granular libs for the specific vision APIs. Models are added as regular assets and you need to ensure that they are not compressed. Overall it was equally straightforward to get both of them up and running.
For the specific Object Detection use case, TFLite has an ObjectDetector class that contains a set of APIs to simplify the implementation. You can easily set base parameters such as the number of threads, number of objects to be detected, minimum confidence score, and other settings that make the integration seamless.
I was still able to provide these same functionalities using PyTorch Mobile but I had to implement them myself from scratch.
TFLite comes with an ImageProcessor object to perform a whole set of transformations to images and get them ready to be fed into the model. I had to manually implement these on PyTorch Mobile.
For the images to be processed by the frameworks, they need to be converted to Tensors first. Both libs have APIs that do this easily.
TFLite is the winner in this category due to the more mature and extended set of APIs.
2. Inference speed
To provide an even-handed and identical comparison of inference speed, I should’ve used the exact same models with the exact number of parameters, which wasn’t the case in my experiment. It didn’t matter too much as TFLite is the only lib that has GPU support out of the box. PyTorch Mobile has released an initial version of GPU support but it’s still in its early stages and it is only presented as a prototype now.
To understand how important GPU usage is and how it affects inference time, find below a table representing the average object detection time using the different computing settings on TFLite.
| Type | Inference time (ms)*|
|--------------------|---------------------|
| TFLite CPU | 28.58 |
| TFLite GPU (NNAPI) | 11.18 |
* Average over 10 samples, inference time includes converting bitmap
to tensor + actual inference time.
Using GPU, inference time is almost 3x faster. Considering that most modern mobile phones already contain a GPU, TFLite is the winner in this section, at least until GPU support for PyTorch Mobile is fully stable and we can properly compare them.
3. Size
One of the key reasons why we can’t run certain models on mobile devices is the size of the models themselves. Storage size in mobile devices is minimal. On top of that, models cannot be obfuscated/shrank using Proguard/R8 out of the box, so the model size will directly impact the app size.
For that reason, we need the framework running the model to be as lightweight as possible. I checked the size of both frameworks on the release variant, minimizing with Proguard/R8 and these were the results. Old Size is PyTorch Mobile, New Size is TFLite.
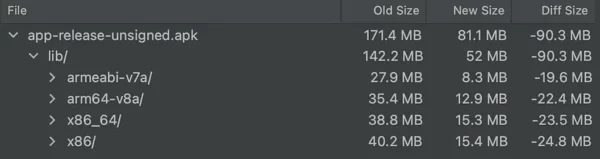
Depending on the architecture, we see a reduction of 19.6MB up to 24.8MB when using TFLite, making it the clear winner of this section.
4. Official Support and Community
Last but definitely not least. Having a trusted community and official support gives developers peace of mind. Knowing that there is a team listening to bug reports or feature requests, and actively contributing to the library is a key factor.
We don’t want to spend time integrating a library into our project if we know that it will become stale soon and no longer be maintained.
A quick search through the TFLite and PyTorch Android Open issues demonstrates that there is an active community contributing to and keeping track of these. Documentation from TFLite and PyTorch Android is equally good. Both are open source as well.
TFLite has more official demo apps compared to PyTorch Mobile (19 vs 7 samples), but both cover the main use cases of Image Segmentation, Object Detection, Speech Recognition and Question Answering.
It’s a tie on this final section.
Conclusion
It was no surprise that TensorFlowLite, after all, would be the recommended framework for mobile inference. Maturity, GPU support, lib size, and the large range of APIs are the key points for this decision.
PyTorch Mobile remains a plausible option, especially considering that PyTorch itself (the full-sized library, not the mobile version) has become a standard among the research community. I’d also keep an eye on the official GPU support release to re-evaluate this decision.
If you want to check out the GitHub repository and experiment yourself:
Stay tuned and follow for other experiments using ML frameworks on Mobile. I am planning to do a similar post running an on-device LLM on Android, coming soon!
This blog is previously published on proandroiddev.com





