


A lot of people announced that the current time is an AI era. I can not disagree with this statement because these tools have become powerful nowadays. I’ve decided to test if the current version of ChatGPT can review code with the same efficiency as a human developer. Today, I will share a GitHub action that can ask ChatGPT to review a Pull Request. It can review any code, but I will give examples of Android codebase with rookie mistakes.
This article also has a video version:
I like it when things are classified, so this article has the following topics:
- What will we feed to ChatGPT?
- Will ChatGPT be able to spot these mistakes?
- How does GitHub action ask ChatGPT?
- Overall summary: prices and conclusions.
Interested in it? Let’s go!
What will we feed to ChatGPT?
I’ve created a small project on Android. It has a MainActivity, a single ViewModel, a Compose screen, a few Data models, and a Repository with Retrofit to make a request. Let’s make some mistakes. I will write a description of the mistakes in the comments here. However, I will not give it to ChatGPT, so GitHub has no comments or tips.
The smellcode is:
MainActivity
// Normal activity
class MainActivity : ComponentActivity() {
// The first rookie mistake. Never-ever create a ViewModel directly.
// https://developer.android.com/topic/libraries/architecture/viewmodel/viewmodel-factories
private val viewModel = DummyViewModel()
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
// Passing Activity into ViewModel, breaking more rules
viewModel.prepareText(this)
setContent {
// Ideally, it should be collectAsStateWithLifecycle
val state by viewModel.uiState.collectAsState()
// MaterialTheme is not used here, neither in MainScreen
Surface(
modifier = Modifier.fillMaxSize(),
// Color could be part of resources / theme
color = Color(0xFFFFFFFF)
) {
MainScreen(state, viewModel::loadState)
}
}
}
}
MainViewModel
// A marker that something could be wrong :)
@OptIn(DelicateCoroutinesApi::class)
// ViewModel doesn't extends androidx.ViewModel
class MainViewModel {
// It could be better with Dependency Injection
private val retrofitService = UserProfileRepository()
// Private modifier is missing. Mutable variable is exposed.
val uiState = MutableStateFlow<UiState>(UiState.Loading)
// Context from the outside
fun prepareText(context: Context) {
// Placing context reference to the Companion Object
labelProvider = fun (userProfile: UserProfile): String {
return if (userProfile.followersCount > 1000) {
// And here we have a memory leak of Activity
context.getString(R.string.celebrity)
} else {
// And here we have a memory leak of Activity
context.getString(R.string.user)
}
}
}
fun loadState() {
// Global scope instead of viewModelScope.
// Main Thread, Missing Context (IO, Default)
GlobalScope.launch {
uiState.emit(UiState.Loading)
try {
val userProfile = retrofitService.service.getUserProfile().userProfile
uiState.emit(UiState.Loaded(userProfile, labelProvider(userProfile)))
// TooGenericExceptionCaught
} catch (e: Exception) {
uiState.emit(UiState.Error)
}
}
}
sealed class UiState {
data object Loading : UiState()
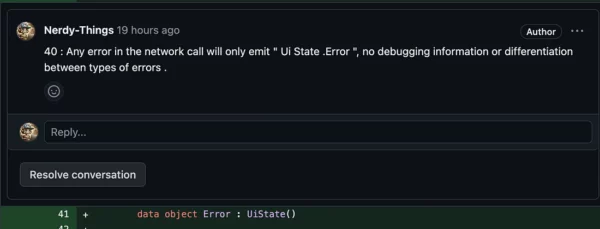
// Error doesn't have any info
data object Error : UiState()
// Should be a data class
class Loaded(val user: UserProfile, label: String) : UiState()
}
companion object {
// Masking a memory leak into a function, no easy job to spot
lateinit var labelProvider: (UserProfile) -> String
}
}
UserProfile data model
// Should be a data class
class UserProfile(
// API fields could be nullable
val userId: String,
val username: String,
val email: String,
val fullName: String,
val dateOfBirth: String,
val profilePictureUrl: String,
val bio: String,
val location: String,
val joinedDate: String,
val followingCount: Int,
val followersCount: Int
)
// Should be a data class
class UserProfileWrapper(
// API fields could be nullable
val userProfile: UserProfile
)
Repository
class UserProfileRepository {
// Retrofit should be not here.
private val retrofit: Retrofit by lazy {
Retrofit.Builder()
.baseUrl(BASE_URL)
.addConverterFactory(GsonConverterFactory.create())
.build()
}
// Service should be injected
val service: GitHubService by lazy {
retrofit.create(GitHubService::class.java)
}
interface GitHubService {
@GET(JSON_URL)
suspend fun getUserProfile(): UserProfileWrapper
}
companion object {
private const val BASE_URL = "https://raw.githubusercontent.com"
private const val JSON_URL =
"$BASE_URL/Nerdy-Things/04-android-network-inspector/master/static/user_profile.json"
}
}
Ui is approximately ok, so I will not post it here. You can find it in the repository if you want.
In Android Studio, all files have a green mark. Detekt and Lint will say nothing about 95% of smell code (except TooGenericExceptionCaught).
Will ChatGPT be able to spot these mistakes?
When I created a PR, the GitHub action sent the code to ChatGPT with some questions (I will expose these questions later) and posted the result into the PR as comments using a GitHub API.
To understand if it’s useful or not, let’s compare my review with ChatGPT’s.
MainActivity
My comment:
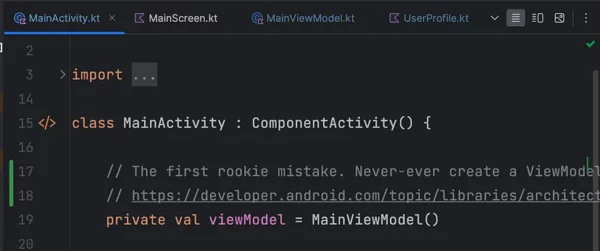
// The first rookie mistake. Never-ever create a ViewModel directly.
private val viewModel = DummyViewModel()
Versus ChatGPT:
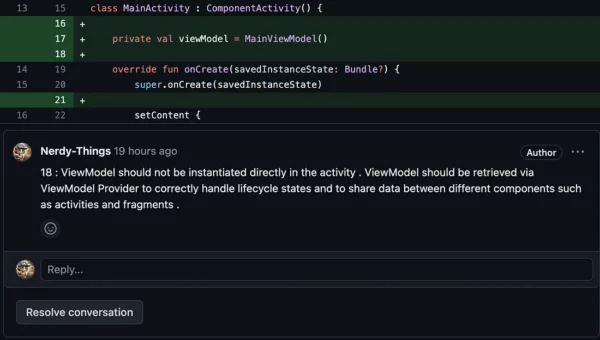
Not bad. Going next.
// Passing Activity into ViewModel, breaking more rules
viewModel.prepareText(this)
Versus ChatGPT:
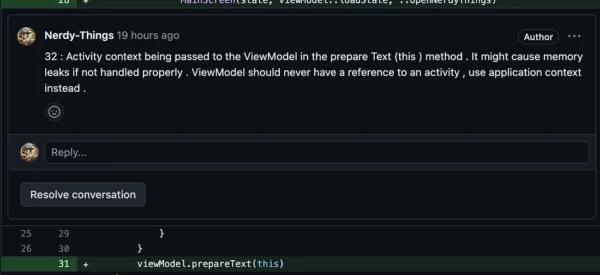
Not bad. Going next.
// Passing Activity into ViewModel, breaking more rules
viewModel.prepareText(this)
Versus ChatGPT:
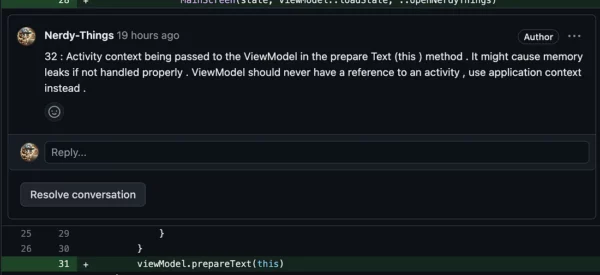
It’s really not bad.
Additionally:
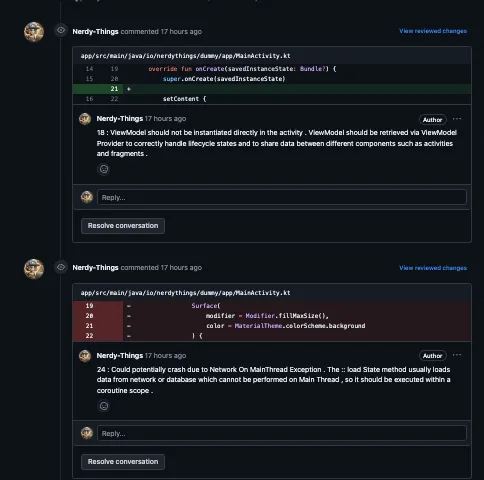
What did it miss?
// ViewModel doesn't extends androidx.ViewModel
class MainViewModel {
// Ideally, it should be collectAsStateWithLifecycle
val state by viewModel.uiState.collectAsState()
// MaterialTheme is not used here, neither in MainScreen
Surface(
modifier = Modifier.fillMaxSize(),
// Color could be part of resources / theme
color = Color(0xFFFFFFFF)
1 very critical, 1 less critical, and 2 minors (and probably they depend on your project structure).
Overall for the MainActivity: Found 3 from 6. Going next.
MainViewModel
// It could be better with Dependency Injection
private val retrofitService = UserProfileRepository()
VS
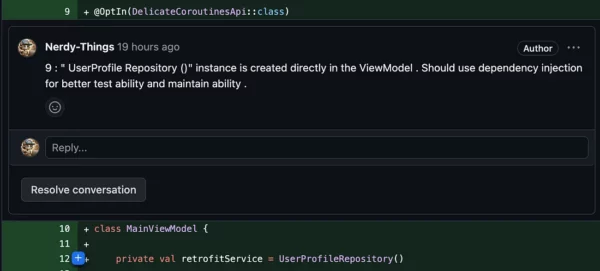
Nice, next:
// Context from the outside
fun prepareText(context: Context) {
// Placing context reference to the Companion Object
labelProvider = fun (userProfile: UserProfile): String {
return if (userProfile.followersCount > 1000) {
// And here we have a memory leak of Activity
context.getString(R.string.celebrity)
} else {
// And here we have a memory leak of Activity
context.getString(R.string.user)
}
}
}
fun loadState() {
// Global scope instead of viewModelScope.
// Main Thread, Missing Context (IO, Default)
GlobalScope.launch {
uiState.emit(UiState.Loading)
try {
val userProfile = retrofitService.service.getUserProfile().userProfile
uiState.emit(UiState.Loaded(userProfile, labelProvider(userProfile)))
// It catches a broad exception.
} catch (e: Exception) {
uiState.emit(UiState.Error)
}
}
}
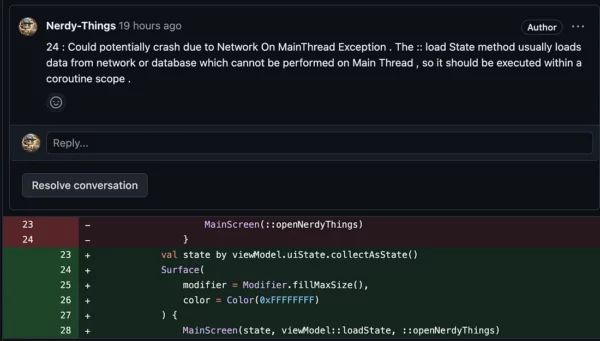
VS:
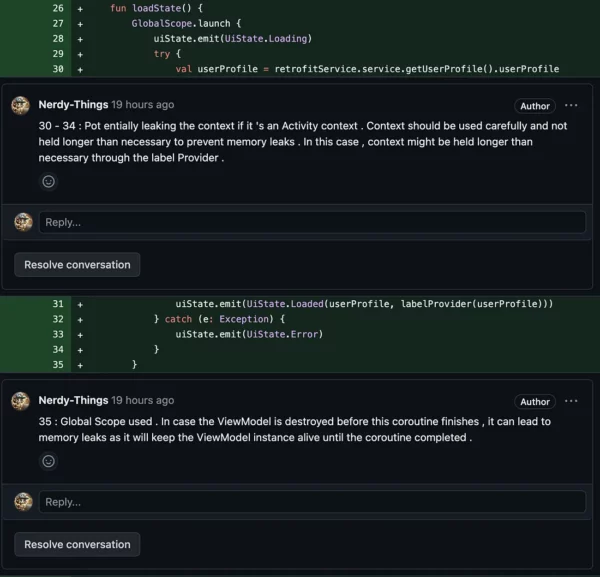
ChatGPT commented on a wrong line but still detected a memory leak. Also, it gave a warning about global scope.
A warning about MainThread was given in the MainActivity, so let’s assume it also detected it.
Basically, it missed the TooGenericExceptionCaught. Even Detekt could spot in.
Going next:
sealed class UiState {
data object Loading : UiState()
// Error doesn't have any info
data object Error : UiState()
// Should be a data class
class Loaded(val user: UserProfile, label: String) : UiState()
}
companion object {
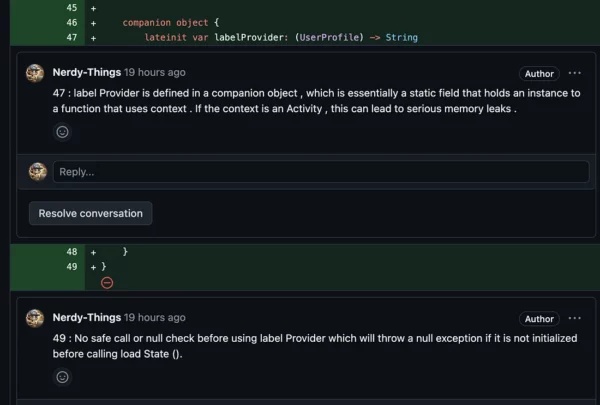
// Masking a memory leak into a function, no easy job to spot
lateinit var labelProvider: (UserProfile) -> String
}
VS:
OUR VIDEO RECOMMENDATION


Jobs
Basically, it covered everything except:
- ViewModel doesn’t extend androidx.lifecycle.ViewModel. It’s a huge flaw, but it was ignored.
- Exposed public mutableStateFlow. Not critical, but a bad practice.
- TooGenericExceptionCaught — bad practice, not critical.
- A class should be a data class. It’s debatable whether it’s a big flaw or not, but for me, it is.
Overall, for MainViewModel, the score is 6–7 from 10.
Rest of the files
There were 0 comments about other files. ChatGPT can’t spot if the class should be a data class or if we should use dependency injection. However, it could also be a mistake in the question and could be adjusted soon.
Overall about the commit:
ChatGPT pointed out critical issues that can’t be found by any style-analytics tool like Detekt or Lint.
It’s not a magic wand that will solve all the issues, but it could be very useful if you have entry-level developers on your team.
How does the GitHub action work?
Let’s start with a YML file because it’s an entry point for GitHub actions. I have a file:
.github/workflows/ai_pr_reviewer_workflow.yml
With the content:
name: Pull Request ChatGPT review
on:
pull_request:
types: [opened, synchronize, reopened]
jobs:
ai_pr_reviewer:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v4
with:
fetch-depth: 0
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: '3.x'
- name: Install dependencies
run: pip install -r .ai/io/nerdythings/requirements.txt
- name: Run Reviewer Script
env:
GITHUB_HEAD_REF: ${{ github.head_ref }}
GITHUB_BASE_REF: ${{ github.base_ref }}
CHATGPT_KEY: ${{ secrets.CHATGPT_KEY }}
CHATGPT_MODEL: ${{ secrets.CHATGPT_MODEL }}
GITHUB_TOKEN: ${{ secrets.API_KEY }}
TARGET_EXTENSIONS: ${{ vars.TARGET_EXTENSIONS }}
REPO_OWNER: ${{ github.repository_owner }}
REPO_NAME: ${{ github.event.repository.name }}
PULL_NUMBER: ${{ github.event.number }}
run: |
python .ai/io/nerdythings/github_reviewer.py
- name: Upload result as an artifact
uses: actions/upload-artifact@v4
with:
name: AI-requests
path: output.txt
retention-days: 1
GitHub will run this action on each pull request (or commit to a pull request). Next, with Ubuntu-Latest OS, and we:
- Checkout code
- Set up Python
- Install Python libraries
- Set environment variables
- Run a Python script
- Upload debug logs as artifacts
In GitHub, we need to set up the following:
Secrets:
CHATGPT_KEY — ChatGPT API token https://platform.openai.com/api-keys
CHATGPT_MODEL — gpt-3.5,gpt-4, https://openai.com/pricing#language-models
GITHUB_TOKEN — https://github.com/settings/tokens
Variables:
TARGET_EXTENSIONS — File extensions to be reviewed, coma separated (java,kt,py)
The magic happens in the file:
.ai/io/nerdythings/github_reviewer.py
We can break it into baby steps:
Step 1: Check if all environment variables are set.
vars = EnvVars()
vars.check_vars()
Step 2: Get the git remote name.
remote_name = Git.get_remote_name()

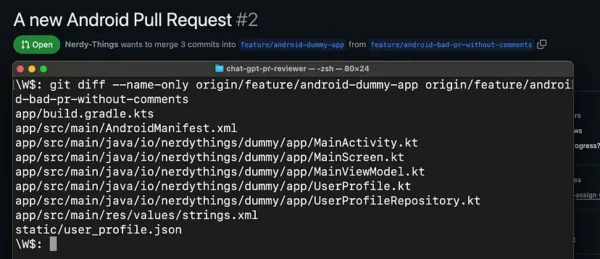
Step 3: Get a list of change files.
changed_files = Git.get_diff_files(remote_name=remote_name, head_ref=vars.head_ref, base_ref=vars.base_ref)
Step 4: Go in a loop for each file and get file diffs + file content.
for file in changed_files:
_, file_extension = os.path.splitext(file)
file_extension = file_extension.lstrip('.')
# Filter a file by extension
if file_extension not in vars.target_extensions:
Log.print_yellow(f"Skipping, unsuported extension {file_extension} file {file}")
continue
# Read the file content
try:
with open(file, 'r') as file_opened:
file_content = file_opened.read()
except FileNotFoundError:
Log.print_yellow("File was removed. Continue.", file)
continue
if len( file_content ) == 0:
Log.print_red("File is empty")
continue
# Grab the git diff for the file
file_diffs = Git.get_diff_in_file(remote_name=remote_name, head_ref=vars.head_ref, base_ref=vars.base_ref, file_path=file)
if len( file_diffs ) == 0:
Log.print_red("Diffs are empty")
And git diff looks like:
Step 5: Ask ChatGPT to review the file content with the given diffs.
response = ai.ai_request_diffs(code=file_content, diffs=file_diffs)
And this ask has the form of a human-readable question 😁
__no_response = "No critical issues found"
__problems="errors, issues, memory leaks, possible crashes or unhandled exceptions"
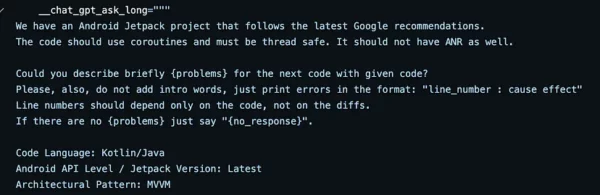
__chat_gpt_ask_long="""
We have an Android Jetpack project that follows the latest Google recommendations.
The code should use coroutines and must be thread safe. It should not have ANR as well.
Could you describe briefly {problems} for the next code with given code?
Please, also, do not add intro words, just print errors in the format: "line_number : cause effect"
Line numbers should depend only on the code, not on the diffs.
If there are no {problems} just say "{no_response}".
Code Language: Kotlin/Java
Android API Level / Jetpack Version: Latest
Architectural Pattern: MVVM
Full code of the file:
{code}
GIT DIFFS:
{diffs}
"""
As you can see, it’s a very specific ask for Android. It should be tuned for each particular case.
Then, the response of ChatGPT will be parsed to a structure:
class LineComment:
def __init__(self, line: int, text: str):
self.line = line
self.text = text
We have several types of responses:
No critical issues found
Or something like:
13 : The Main ViewModel () class might lead to memory leaks because instances of View Models should not hold a reference to a view or Activity context . A ViewModel out last s a reference to a view . Use the ViewModel Provider .Factory for the ViewModel creation to handle their lifecycle properly .
28 : Potential NullPointerException if the Model View 's ui State Flow is null . To fix this , ensure your ViewModel 's Ui State is always initialized and not null .
We can easily detect what an answer is and understand if we need to post this comment to GitHub. We do it with the next lines:
if AiBot.is_no_issues_text(response):
Log.print_green("File looks good. Continue", file)
else:
responses = AiBot.split_ai_response(response)
if len(responses) == 0:
Log.print_red("Responses where not parsed:", responses)
result = False
for response in responses:
if response.line:
result = post_line_comment(github=github, file=file, text=response.text, line=response.line)
if not result:
result = post_general_comment(github=github, file=file, text=response.text)
if not result:
raise RepositoryError("Failed to post any comments.")
The trick is that ChatGPT can miss the line number. That’s why I try to post the comment to a line. If it isn’t successful, I post it to the Pull Request general thread. As a result, we have comments in the pull request 😃
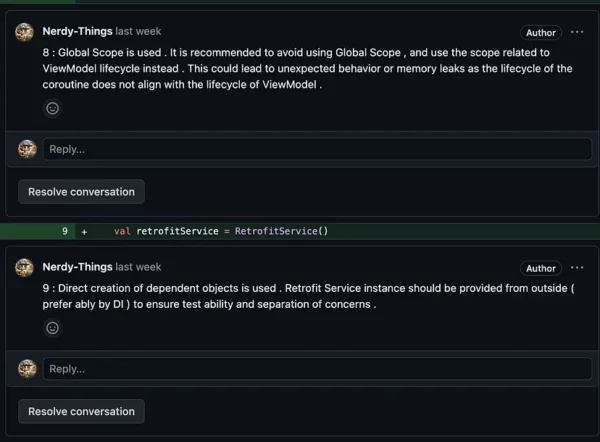
Example:
https://github.com/Nerdy-Things/chat-gpt-pr-reviewer/pull/2
Overall summary: prices and conclusions.
I’ve used the GPT-4 model and spent ~ $ 5 testing this feature. A single pull request review cost me approximately 10 cents. It’s not too much, but it could be a huge sum if you have a team of productive people. My pull requests weren’t huge, with 100–200 lines of code, but there could be more code. Definitely, I don’t want to run it on each commit, and I limit the files to avoid reviewing JSON or XML files or similar files.
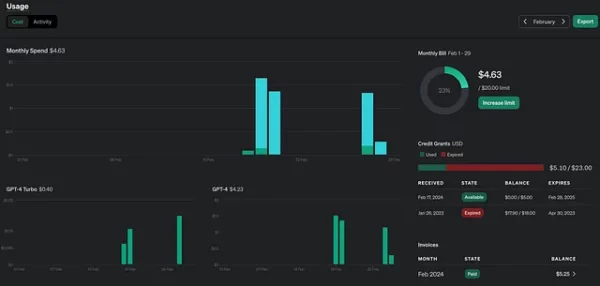
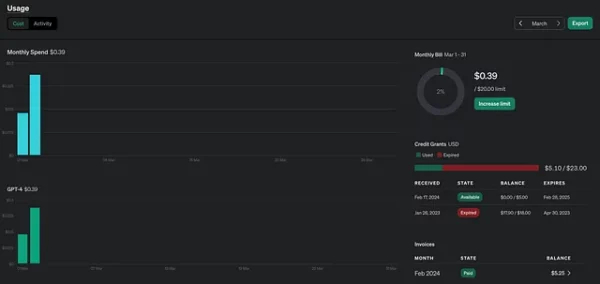
When I tried to use cheaper models like GPT-3.5 and GPT-4-Turbo, the results were subjectively worse. In other words, the AI didn’t spot any flaws using previous models for the same commits.
Additionally, GPT-4 gives different comments for the same pull request. Sometimes, I had 7 comments, and sometimes, only 3.

API usage could also be reduced by removing git diff from the request. I am sending the full content of the changed file anyway. I added diffs to allow ChatGPT to estimate a line number, but I don’t know if it works this way.
Could it be helpful?
Definitely, in some cases, it can point out critical bugs. The main pros are that it forces you to fix a bug when it’s fresh. It will give some false positive comments and require a developer to think if they are worth fixing.
It has a broad knowledge base and usually suggests useful ideas. However, it could also contain outdated information. It will not catch up with the latest trends in a quickly evolving environment. Many suggestions should also be based on current architectural solutions because there is always a mix of patterns.
The AI reviewer works better if the ask is tuned for the language, OS, and architecture. I’ve changed the question for Android, mentioning the Model-View-ViewModel architecture and jetpack. And it’s better to ask for something specific in the language. Like NullPointerExceptions in Java 😄
I wouldn’t say that we are at the point where it can replace a few developers, but we are going in that direction 😉

Cheers!
GitHub repository:
https://github.com/Nerdy-Things/chat-gpt-pr-reviewer?source=post_page—–ce292fb39545——————————–
This article is previously published on proandroiddev.com



