

I have been building reactive, fully asynchronous, high-performance, multiplatform apps for multiple years now. Over time, I have stumbled upon a few difficult, tricky-to-find, hard-to-debug issues with state management. In this article, I would like to share my experience with you so that hopefully you won’t have to go through the same problems I went through, and to propose a new approach to state management I have never seen before that will free you of these issues for good.
So the story begins when reactive apps using MVI / MVVM+ became popular and I started taking my first steps in learning to build them. In this article, I will mostly be talking about MVI because state management in MVI is slightly more advanced so the examples are going to be more illustrative, but the same problems and solutions apply to MVVM (which also has state(s) to manage).
Remember that time when UDF became a fad and we all started using it? That time produced very distinct bugs in some applications that I will call “inconsistent state problem” (ICS). Let me show you a real-world example:
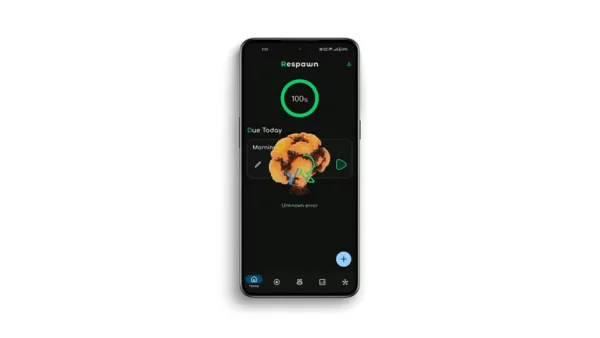
See this? The app displays both Loading, Error, and Success states at the same time. Whoops! I’m sure you have experienced or are about to experience something similar when working with UDF.
In this article, we’re going to solve this problem for good.
Starting off: What is a state? What is a state transaction?
Let’s start by exploring what state is in the context of this article and what “state transactions” are.
I define the Application State as:
An object or multiple objects that are being held in memory that represent the condition of the application at a given point of time and are serving the purpose of holding the snapshot of the data necessary for the functionality of the app.
In simpler terms, this means that I define state as:
A class that represents the most recent data that the application has received from multiple sources of truth
The example of the state you may be most familiar with is the UI state:
data class UIState(
val isLoading: Boolean = true,
val error: Exception? = null,
val items: List<Item>? = null,
)
Usually, each page (screen) of our app has its own UI state. Sometimes state can be split between different components (e.g. widgets) of the app. But what is a state “transaction”?
A state transaction is an atomic operation that changes the current application state.
State transactions occur all the time. Whenever you want to load items from the Internet or the database, for example, you want to do 3 things:
- Set the state to show a loading indicator
- Request items from a data source and wait for them to arrive
- Set the state to display items
Here, the minimum number of transactions you have to perform is two: One to set the state to loading, and one to set the state to display items.
The reason we must perform state transactions is that our state is by default independent of the state of the source of data. This means, you can have new items arrive into the database table, but your state won’t change and you will show old data unless you do something about it manually. I will talk about how to solve this problem a little bit later.
Let’s now understand the difference between persistent and transient states.
I define persistent state as:
Application state that is independent of the application process lifecycle.
Examples are databases, network servers, web socket connections, SavedStateHandles (on Android), and Files. They all share one trait – they outlive our running application’s lifecycle.
Respectively, transient state is:
Application state that exists while the app process is alive, i.e. state that is stored in-memory.
Examples are loading indicator visibility, text input states, or client<>backend sessions and connections.
According to my definition, applications can only operate using transient states at all times. This means we can’t use the database state directly — we have to observe it and react to its changes, hopefully keeping our transient state in sync with the database state. Can you guess where problems can arise now?
Before we proceed, the last thing we need to clarify is how we can define transient states in our code.
The first method used in MVI is to keep a single state object that represents the accumulation of various data sources and transient sub-states. In simple terms, we only have one state object per business logic component (BLoC). An example of such a state was demonstrated above.
The second method is used in MVVM — it is to have multiple independent state objects that are mutated separately, within a single business logic unit. An example of this would be:
val isLoading = MutableStateFlow<Boolean>(true)
val error = MutableStateFlow<Exception?>(null)
val items = MutableStateFlow<List<Item>?>(null)
Don’t get me wrong — we always have to decompose states, be it MVI or MVVM. We just do it less granularly with MVI by unifying our states within a business logic component (BLoC). Read along to get an explanation of why we may want to do this.
Step 1: Making State Reactive
With UDF, our goal is to make the Application State dependent on the Data Source State.
For example, instead of manually setting the state to display items (step 3), we can make our state a slave to the data source state. This means that we will watch for changes in the database state, and when the new data arrives, we will automatically update the state with that data. In our example, we can do this with database triggers, which are usually provided by the ORM. We will subscribe to an observable data stream in our business logic to watch for those changes. Mind this — we haven’t eliminated a transaction from the example above, we just made it automatic, decoupled from our logic.
So from the client’s (developer’s) standpoint, our flow is now:
- Set the state to show a loading indicator
“Wait — but where’s the rest?” — you may ask. That’s to me the biggest promise of UDF — we are trusting that our state will always come from a reliable data source so that we do not have to manage it ourselves. In our case, we just have to “begin” with a loading indicator, and our database trigger will do the rest by requesting new data and observing its changes. When the data is loaded, some other part of our code will set our transient state to match the persistent one. We can do the same with network requests by wrapping them in reactive streams such as Coroutines’ Cold Flows:
val items = flow {
api.getLatestItems()
}
As simple as that, when we subscribe to our flow, the framework will lazily execute our request and retrieve the data once, then reuse it until we leave our BLoC’s lifecycle.
In the case of a state that is not backed by a data source (it’s originally and wholly transient), we can just create an observable object such as a hot Flow, and mutate it when the data changes, manually. Our clients will get notified of the change the same way as with persistent state. We are kind of our own database trigger in this case.
val username = MutableStateFlow<String>("")
fun onUsernameChanged(value: String) = username.value = value
Instead of changing the state directly, we change an observable stream’s value by hooking into the actions the user takes on the UI and delegate the changes to be stored in our username property.
Step 2: Unifying States
So now let me talk about why we may want to unify our state and when we shouldn’t.
State is usually unified with MVI, and we do this for the following reasons:
- We provide a single, well-defined access point for our application state, ready to be consumed by clients
- We explicitly define all related changes to the state within a single transaction (and as a result, within a single easy-to-understand code block)
- We reduce the number of state transactions when a lot of variables can change, gaining performance
- We make consuming and changing related states easier by grouping their properties together
- We protect ourselves from accessing the data which we should never had access to, during compilation.
To me, the biggest benefit is #5. If we unify our states right, we can be sure that we don’t access what we shouldn’t have even before we compile our application.
Take a look at the MVVM example from before:
val isLoading = MutableStateFlow<Boolean>(true)
val error = MutableStateFlow<Exception?>(null)
val items = MutableStateFlow<List<Item>?>(null)
Can you see a problem here now? We have to declare a bunch of variables that are null or “empty” because very often, they are simply not present. We also have to account for the fact that the list of items can not only be empty but also missing.
In my humble opinion, this greatly complicates our business logic:
- We have to always check if the value is present, even if we are sure that it will be present in some particular place
- We have to always keep references to values despite not needing them very often
- We have to always make sure to clean up every single value during each state manipulation to notify our code that the value has gone missing and keep our UI consistent
- We have to pass all these values to our UI and manage them there, complicating our code. We also have to manage the resulting boilerplate
These are the main reasons that I prefer to unify my states to a reasonable degree when using MVI. That’s also probably the reason Google (and most commercial modern apps with it) are moving away from traditional MVVM and towards MVVM+ (which is the same but has unified states).
You may say: “But I can create a single class and it will still have the same problems!” citing my first example:
data class UIState {
val isLoading: Boolean = true,
val error: Exception? = null,
val items: List<Item>? = null,
}
Here’s where I propose a new paradigm for describing your state using the power of the programming language — to move to State Families, as I call them.
Step 3: Making State Consistent with State Families
In essence, the term “State Family” means that:
We define Application State as a closed list of distinct, unrelated objects representing the current type of the state of our application.
In Kotlin, this would mean that we will define our state as a sealed interface, and remove all the properties that cannot be present when the app has this state, from the resulting object:
internal sealed interface EditProfileState {
data object Loading : EditProfileState
data class Error(val e: Exception?) : EditProfileState
data object Success : EditProfileState
data object DisplayingAccountDeleted : EditProfileState
data class EditingProfile(
val email: String, // data from repository
val name: Input, // value the user typed
) : EditProfileState
}
Why I call this “Semi” state machines or “State Families” is that unlike strict state machines, we do not define the transitions between states, as there can be too many of them. That is often not needed in client applications. Can you already see the benefits of this approach?
- When we display a
Loadingstate, we are sure that there are no data or errors and will never be. We cannot access these values to mistakenly display them to our users or manipulate them. - When we show an
ErrororEditingProfilestates, we no longer have optional (nullable) fields that serve no purpose. When the state isError, we are 100% sure there is an error to display and nothing else. - Our state is grouped in one place, strictly defined on what it can look like, and has a well-defined contract on what must be present, what must be missing, and what is optional when we present a particular state.
- We can have as many states as we want, we can have “Nested states”, and we can produce this state family using any combination of data sources (even using our old code where we had a bunch of flows!)
Look, we are a long way ahead now! Here’s what we achieved with our paradigm shift:
- First, we reduced the number of states and state transactions drastically by using UDF and reactive streams, freeing us from the quirks of state changes.
- Then we unified our state, thus simplifying our business logic, making our code easier to understand and extend, and reducing the number of bugs by removing all but one point of access to our application state and related transactions
- Finally, we defined our state as a closed family of types, eliminating all risks of accessing the particular values when we shouldn’t both in the business logic and in the client (i.e. UI) logic. We also got ourselves a visual, simple-to-understand code structure and a single place where we can store and manage all of our state transactions and values.
Unfortunately, this approach is not without its drawbacks. We now have two other problems on our hands…
Solving the Problem #1: Lost information
Since we now have a singular source of truth and a distinct family of states, we can no longer “preserve” our previous values when the state changes.
For example, our Loading state does not contain the email, or what the user entered as their new username. Whenever we want to show a loading indicator to validate the new username, for example, we lose all information about the previous state of the application.
This problem can be solved very easily by passing the state around to whatever code that may need to restore the state to a previous value or use it for its needs, but it requires a slight paradigm shift in our thinking. When we now want to validate the user’s password, we will now need to pass the previous state down the call hierarchy:
val state = MutableStateFlow<EditProfileState>(Loading)
fun onSaveChangesClicked(state: EditingProfile) {
state.value = Loading
validateNameAsync(state)
}
fun showValidationError(e: Exception) { /* display a snackbar etc */ }
fun validateNameAsync(previous: EditingProfile) = launch {
try {
repository.verifyNameIsUnique(previous.name)
state.value = Success
} catch (e: Exception) {
state.value = previous
showValidationError(e)
}
}
See? We now grab the state when we start an operation, launch it asynchronously, and then set the state to Loading. Our operation can show either Success depending on the result, or display a validation error and restore the state to the previous one using the accessed parameter.
The code looks slightly different now — it appears as if we never restore the state or show a success message (It makes no sense right now, but I’ll explain why this weird order in a minute).
OUR VIDEO RECOMMENDATION


Jobs
Solving the Problem #2: Managing the type of the object
Kotlin is a statically typed language, and because of that, we need to cast the state to a particular value safely to be sure we don’t crash the app. We need to cast because sometimes we want to access some properties of the previous state if they are present.
For example, whenever we want to update the current state with the new data from an outside source (remember UDF stuff above?), we don’t know what the current state is. Kotlin’s syntax is quite annoying in this case, but by doing all of this, we are explicitly following our contract during compilation and thus getting the benefits of our previous improvements. For example:
class EditProfileContainer(
private val repo: UserRepository,
) {
val state = MutableStateFlow<EditProfileState>(Loading)
override suspend fun onSubscribed() { // (1)
repo.getUserProfileFlow().collect { user: User ->
state.update { state: EditProfileState -> // (2)
val current = state as? EditingProfile // (3)
EditingProfile( // (4)
email = user.email,
name = current?.name ?: Input.Valid(user.name ?: ""), // (5)
)
}
}
}
// not using the "update()" function for illustration purposes
fun onNameChange(value: String) {
state.value = (state.value as? EditingProfile)?.let {
it.copy(name = Input.Valid(value))
} ?: state.value // (6)
}
}
1. This is important: We should only watch for persistent state changes when the user sees the page, not in the background. Otherwise, we are wasting resources for nothing and the user may never see the changes. This requirement is new, it appeared because our state is now a Hot Stream of data, and requires a custom lifecycle handling implementation.
2. Each time we get an update from our data source, we want to use that data to transition from a loading state to a new EditingProfile state. Why? Because the new data has arrived, so there is no point in keeping the loading indicator present. In any case, we don’t know if there is a point now.
3. We check for the type of the current state safely to see if the state is already containing some data. In our example, a “Name” form field. We now have to safely handle both cases — when the value is and is not present.
4. We assemble a state where we are no longer loading and are supposed to display the data instead, but we need to provide the required values now. Otherwise, if our state is invalid, we won’t be able to compile the app
5. We are now forced to first check if the user has already made changes to their name.
- If yes, we just use the previous value. We have successfully preserved the changes the user has made.
- If not, we first check if the user has set a value in the remote user object. It’s a good UX to show the user their previous username if they want to make a small change.
- If neither are present, we suggest the user add a username and populate the input form with an empty string.
6. If the state is not of the type we wanted, we just skip the operation. The user was probably spamming buttons or the processes are being executed in parallel and the state is changing.
I know — the code above looks slightly more complicated at first, but I would argue we can solve that easily as well:
- We can abstract the logic of
onSubscribeinvocations by using or creating an architectural framework. - We can simplify the visual look and boilerplate of those type casts by creating a nice DSL that will do all the type checking for us.
- For each specific use case, we can create simple extensions to do the boilerplate for us if we don’t like how our code looks. For example, we could create a function:
fun Input?.input(default: String? = null) = this ?: Input.Valid(default ?: "")
// usage:
EditingProfile(
name = current?.name.input(user.name),
)
Here’s how my code for this feature looks after some refactoring:
val store = store<EditProfileState>(Loading) {
whileSubscribed {
repo.user.collect { user ->
updateState {
val current: EditingProfile? = typed<EditingProfile>()
EditingProfile(
email = user.email,
name = current?.name.input(user.name),
)
}
}
}
fun onNameChanged(value: String) = updateState<EditingProfile, _> { // this: EditingProfile
copy(name = value.input())
}
}
Not so scary anymore? My opinion is that this not only gets all the benefits we discussed before but also looks and reads like English, which is golden for our fellow teammates and us in the long term.
So now we just got to solve our last problem, the most insidious one and one you may not have even been aware of till now.
Step 4: Making State Updates Parallel
Whenever we create applications in the modern, reactive world, our users expect nothing less than to have their experience always be fluid, consistent, performant, and stable. With the rising demands on the quality of client applications, we developers have to put in more and more effort into ensuring that we always deliver the best possible UX with animations, progressive content loading, database caching, and reactive data streaming. This demands for us to do 2 things:
- We make our applications fully reactive and multithreaded
- We execute operations in parallel and in the background
- We ensure our app handles errors and frees resources during concurrent operations
- We display proper feedback to the user at all times
Remember the times when we could just slap a blank screen while the data was loading and show a full-screen error if it wasn’t able to, and the users wouldn’t mind much? I think those times are gone, and now a blank screen for even a second can be an easy 1⭐️ review and a full-screen loading indicator will now ensue the wrath of the UX designer on your team complaining about retention metrics.
Ensuring all 4 of the criteria are met is extremely challenging and requires in-depth knowledge of parallelism, thread synchronization principles, and asynchronous frameworks like Coroutines.
For a practical example, let’s say we made our EditProfileContainer run on a background thread and we added an input validation that checks if the username is unique.
fun onNameChanged(value: String) = updateState<EditingProfile, _> { // this: EditingProfile
val new = copy(name = value.input())
launchValidateUsername(new)
new
}
fun launchValidateUsername(state: EditingProfile) = launch {
val unique = repo.verifyUsernameIsUnique(state.name.value)
if (!unique) updateState {
state.copy(name = Input.Error(name.value, "Username is not unique")
}
}
The problem is, when the user is editing their name and stops, the username is sent to be verified, but then if they click “Submit”, the order of state transactions is now undefined because they are parallel now and we have captured the state that went out of the scope of the transaction.
This leads to the following happening, as just one example among others:
- The user changes their name and it is unique
- We start validating the user name, but the operation is quite slow
- The user immediately clicks “Submit”
- We send the value to be saved and set the state to
Loading - While we are trying to save changes, the validation result comes in!
- We update the state to restore the previous value
- The user’s screen flickers and the loading indicator disappears
- The user, not understanding what has happened and why there was no feedback, clicks the “Submit” button again.
- We start updating the state and show a loading indicator again
- The previous save result comes as a success and the user sees a message that their changes were saved
- The next submitted username result comes in. The name is no longer unique and the function throws an error
- The screen flickers and the user sees a message saying their changes could not be saved, despite being saved in reality, just a second after seeing the success message
This is such a terrible user experience! And we just tried to simply do the work on the background thread. The reason this happened is that our state transactions are not serializable.
Step 5: Serializable State Transactions
The term “serializable” actually comes from database architecture (DBA) terminology and has nothing to do with REST or JSON structures.
If you are not familiar with DBA’s quirks, the same problem we just faced existed a long time ago with databases, as their transactions are parallel as well. One transaction can read the data, and while it’s running, another can change that data, leading to a race between two transactions and an undefined result for both.
There are multiple ways database frameworks solve this (and they are ultra-complicated) so we are not going to deep dive into them right now. If you want to learn more, search for “Database transaction isolation”. Instead, let’s solve this problem for good in our application.
But before we do, I must mention that I have never seen this topic even being brought up once in the Kotlin development community before, so what I’m doing here is something either completely new (or a rather specific case of inventing the wheel, your decision), and that’s the main reason I am writing this article.
I investigated this issue on my own and I concluded that most client apps and architectural frameworks use the following approaches:
- Making all operations sequential
– For example, with MVI, we define our Intents as a queue of commands (e.g. with a Channel), and they are processed sequentially as a result. We already said that this approach won’t do for our highly parallel reactive application - Using only the Main (or a single) thread for updating the state
– Frameworks such as MVIKotlin, Orbit MVI, and most others employ this strategy by disallowing background thread state updates. As we said, our goal is to make a fully async, performant application - Splitting the state into multiple streams, updated atomically between threads
– This is the approach of MVVM / MVVM+, but by going back to it, we would lose all the other benefits we just got - Making all states persistent — this one is self-explanatory, but we can’t cover all the possible use cases for this. There are quite a bunch of imperative/stateful platform APIs to deal with, as an example
- Using various flags in the state to indicate the progress of operations and constantly managing all of them
– For example, we could add a flagisValidatingUsernameto our state and check it to decide whether to transition the user to the next state or not and/or cancel the update job when we send the data
– I don’t believe this solution to be satisfactory, not only because we are going back to where we started, trying to get rid of meaningless values, but because also the complexity of such solutions can grow exponentially on us - Manually synchronizing each parallel data source using primitives such as Semaphores and Mutexes
– This one is actually good and is (spoiler) the basis for our solution, but it’s super cumbersome to create and manage locks for everything we have, and it also shifts the responsibility for atomicity downward to the business logic that wants nothing to do with our presentation layer states.
– It will also ultimately slow down our app when we face the usual problems of synchronized code such as deadlocks, livelocks, and thread starvation
I propose something different — why don’t we just learn from databases and make our state transactions serializable? The implementation of this solution is straightforward as well:
private val _states = MutableStateFlow(initial)
val states: StateFlow<S> = _states.asStateFlow()
private val stateMutex = Mutex()
suspend fun withState(
block: suspend S.() -> Unit
) = stateMutex.withReentrantLock { block(states.value) }
suspend fun updateState(
transform: suspend S.() -> S
) = stateMutex.withReentrantLock { _states.update { transform(it) } }
We can extract this code to a delegated interface and be done with this problem forever.
P.S. For those who know the details, this makes our state transactions correspond to Postgres’ SERIALIZABLE transaction isolation level.
I must note that using a reentrant lock here is super important, as we want to support nested state transactions for several edge use cases.
“And that’s it?” — you may ask.
Literally yes. There is a small caveat to this though: you must understand that we introduced synchronization logic to our code which will make the state updates sequential by nature. The lock introduces some overhead in terms of performance each time we try to update the state, so you may want to consider creating a “fallback” approach or an option to disable serializable state transactions for a given update operation or a whole BLoC to prevent resources from being wasted on synchronization when state updates are very frequent. In my personal experience, these slow-downs are seldom noticeable and will not lead to jank if run on the main thread.
Afterword
The biggest benefit of the approach is not solving a single problem or accounting for an edge case, in my opinion, but is that we never have to think about problems of state management again by changing the paradigm under which we operate. We can write fully asynchronous code, run as many parallel processes as we want, and create as complicated state hierarchies and features as we want, all without ever stopping even for a second to doubt if our code will always behave as expected. Using this approach freed an enormous amount of cognitive resources of mine when creating applications, and that’s ultimately what I value the most. I believe that writing code should be an easy, fluid process, where you ideally don’t have to stop to consider another edge case or a possible issue.
I hope that armed with knowledge from this article, you will now be able to make an educated opinion and grab the practices outlined here or implement ideas that will help your apps become better and your workflow more fluid.
After reading this, you may still have a couple of questions left:
- Where can I see this approach in action?
- Where can I see an example implementation?
- What if I don’t want to do all of the things mentioned above on my own, and just want to have a ready-made solution I can set up?
I got you here. Everything we discussed in this article I implemented fully in the architectural framework that I and my teams are using — FlowMVI.
The framework:
- Is making state transactions fully serializable with reentrant locks and the ability to disable serialization for a single transaction or a whole business logic unit
- Has a nice DSL like the one above that simplifies type checks and safe state updates
- Manages the subscription lifecycle for you to run, stop, and relaunch state update jobs
- Allows you to make business logic fully async and switch to any number of threads you want
- Is implemented using coroutines as a first-class citizen
- Makes states consistent and allows to easily unify them into a single source of truth by design
- Handles all errors for you and allows you to update the state accordingly without awkward
try/catches for every function - Abstracts away all the nitty-gritty of state updates and parallel processing so that you don’t have to worry about them ever
- Manages background jobs for you and frees resources at the right moment automatically
- Supports caching, atomic, sequential, or parallel command processing and decomposition of business logic into asynchronous data sources
- Supports persisting your state as needed for an additional layer of safety
I will be happy if you give it a try and let me know what you think of this new approach to state management!
This article is previously published on proandroiddev.com







