

Kotlin, Coroutines, Firebase Crashlytics
Introduction
Recently, we have been making an effort to improve the observability of our mobile apps in production. Our goal is to reduce crashes, as well as to improve the visibility & heuristics of non-fatal errors so that we can address the issues and ultimately improve the user experience(NPS).
The improvements can be boiled down to the exception handling and reporting in the app. I would like to share some practice & tips that we learned along the way and hope them helpful to others in the community.
Our Android app is built with Kotlin, coroutines and integrated with Firebase Crashlytics. So the content in this article is mostly relevant to them.
1. Backstop Errors with CoroutineExceptionHandler
Coroutines is the preferred option to handle asynchronous operations in Android, thanks to its efficiency and its ability to suspend while waiting and resume when a result is ready(this allows the hosting threads to be available for other tasks). The underlying mechanism of suspension and continuation is an entire topic on its own. But if your project is already using Coroutines, here is a hidden gem you might want to discover – CoroutineExceptionHandler.
CoroutineScope & CoroutineContext
All coroutines should start with CoroutineScope, to support an important concept called structured concurrency, which sets up the relationship between parent and child coroutines so that:
1) parent suspends until all children are finished
2) children inherit and overwrite CoroutineContext from the parent
3) job cancellations can be propagated both ways between parent and children
Let’s checkout its definition:
| public interface CoroutineScope { | |
| public val coroutineContext: CoroutineContext | |
| } |
CoroutineScope Interface
CoroutineScope is essentially a wrapper around CoroutineContext. CoroutineContext is often carried around implicitly throughout coroutineslibrary and represents a collection of important Element(interface) instances such as Job, CoroutineName, CoroutineDispatcher, to name a few. One of these elements is CoroutineExceptionHandler. That element seems to be the less known and publicized than others. But it is very useful because it defines the default behavior when the uncaught exceptions are propagated into the root-level coroutine job.
CoroutineExceptionHandler
Here is an example of how to leverage CoroutineExceptionHandler as the backstop to all exceptions in the root-level coroutine and prompt a UI message to users as the default behavior.
| class BaseViewModel<S : BaseState> : ViewModel(), MviViewModel<S> { | |
| private val exceptionHandler = CoroutineExceptionHandler { context, throwable -> | |
| // 1. Trigger event to prompt error dialog | |
| // 2. Log to tracking system for observability | |
| } | |
| private val job = SupervisorJob() | |
| private val context = Dispatchers.Main + job + exceptionHandler | |
| protected val coroutineScope = CoroutineScope(context) | |
| ... | |
| } |
Example Base ViewModel to define CoroutineContext & CoroutineScope
CoroutineExceptionHandler takes a lambda (CoroutineContext, Throwable) -> Unit as argument. There are 2 things to do in lambda:
- With the throwable, we can trigger an event to prompt a default error dialog or render the error state screen to users.
For example, if your architecture has an event stream(LiveData, Flow or RxJava) for UIController(Activity or Fragment)to render error-dialog, emit the error event to the stream. Then render the error dialog in the base classes of UIControllers.
ViewModel -> ErrorEvent -> UIController -> ErrorDialog - Log exceptions to your tracking system, to provide observability in production. In our project, we integrate Firebase Crashlytics with our Timber logger transparently for the release build, which is explained in a later section.
Now, let us briefly go over a few other elements used in the example.
SupervisorJob
When an uncaught exception is thrown, its current coroutine breaks with CancellationException. By default, with the mechanism of structured concurrency, the coroutine builder(launch or async/await) not only cancels itself, but also cancels its parent. In addition, the parent also cancels other children coroutines. In other words, the exception propagation is bi-directional: from child to parent and from parent to children. So the entire structured coroutines will be cancelled.
Many applications probably don’t desire such two-way cascading behavior. For example, in a screen to show both public and private events, if the fetch for the public events failed, you might still want to show private events instead of cancelling everything. The most common way to stop the cancellation cascading is to use SupervisorJob (another alternative: supervisorScope{}). SupervisorJob would ignore the CancellationExceptionand would neither cancel itself nor cancel its children. That nature makes SupervisorJob the most common Job type defined in the root-coroutine.
context = Dispatchers.Main + job + exceptionHandler
Kotlin exhibits a bit magic here with type definitions and operator functions. Both CoroutineContext itself and its Elements(dispatcher, job, exceptionHandler) are the same interface type CoroutineContext. That is why the result can be assigned to the context type. The operator functions(+) make the expression look like an addition so all the elements are aggregated to form the parent CoroutineContext. Anyway, the most important point here is to define our custom exceptionHandler as a part of the coroutineContext for the root-coroutine. As a result, root-coroutine would start in the Main thread, using SupervisorJob, and most importantly, capture all unexpected exceptions.
A Catch of Helper Function viewModelScope { }
Google’s KTX extensions provided ViewModelScope, as a convenient shorthand to kick off coroutines in ViewModel, but let us examine it a little bit. ViewModelScope is defined as a Kotlin extension property on ViewModelas following:
| public val ViewModel.viewModelScope: CoroutineScope | |
| get() { | |
| ... | |
| return setTagIfAbsent( | |
| JOB_KEY, | |
| CloseableCoroutineScope(SupervisorJob() + Dispatchers.Main) | |
| ) | |
| } | |
| ... | |
| } |
Extension Property ViewModel.viewModelScope
The CoroutineContext is defined as a SupervisorJob() & a Main Dispatcher. However, CoroutineExceptionHandler is missing here. The default behavior to handle exceptions is simply to print the stack-trace but followed by the application crashing. So if you want to add backstop to uncaught exceptions and observe errors in production, we should define our own CoroutineContext instead of using the helper viewModelScope.
Result
With the backstop mechanism in place, we’ve observed substantial crash reduction in production. The stats below showed our crash-free rate for a month after the release.
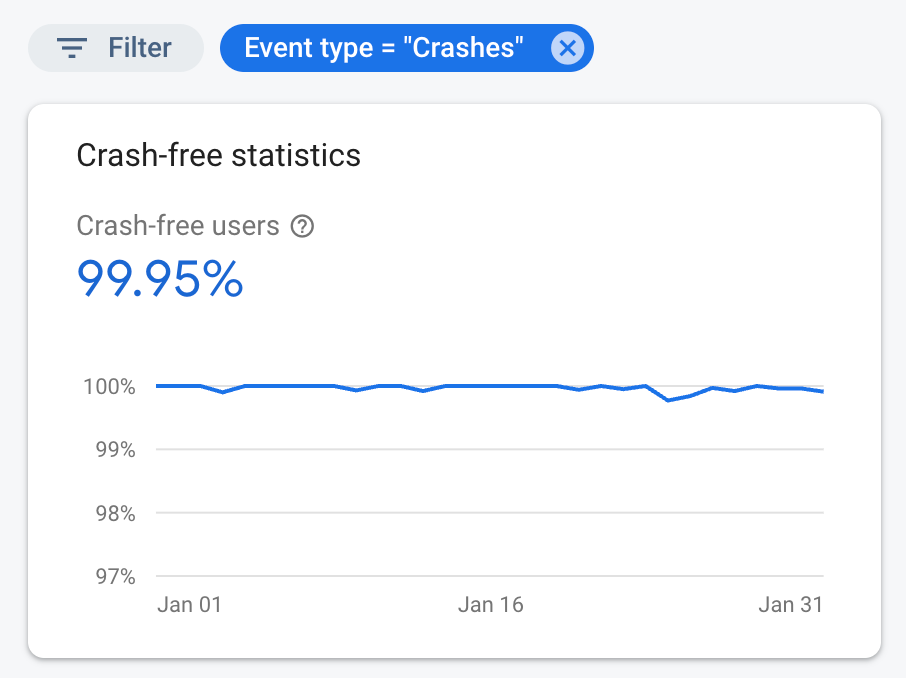
OUR VIDEO RECOMMENDATION


Jobs
2. Centralize Exception Handling In Helper Functions
The previous section explained how to backstop the unexpected exceptions from coroutines. This technique will help reduce the crash-rate of your application drastically, but it only serves as the last defense with a generic error message. We should always strive for capturing errors in the upstream layers, wrapping them into specific Failure result as to provide specific error message or state to users.
On the other hand, catching & logging exceptions is a repetitive job. We want to provide an easy-to-use helper functions for such a task. In principle, we would like those helper functions to achieve the following:
- Offload try/catch/logging ceremony with helper functions and handle exceptions uniformly
- Log with sufficient diagnostic information to identify issues
Helper Function Example
A common pattern in Android is for ViewModel to get the results from the business logic layer (UseCase or Repository, depending on application architectures). Result could be either success or failure. Given an application that uses the Result API from Kotlin (since v1.3) for the results. A help function could be like this:
| internal suspend inline fun <T> getResult(block: () -> T): Result<T> = try { | |
| block().let { Result.success(it) } | |
| } catch (e: Exception) { | |
| // Ensure coroutine cancellation can propagate to parent coroutine | |
| if (e is CancellationException) throw e | |
| // TODO Log with diagnostic information | |
| Result.failure(e) | |
| } |
Sample Helper
The call-sites in the UseCase layer would as simple as:
| val userResult = getResult(repo.getUser()) | |
| ... | |
| val eventResult = getResult(repo.getEvents()) | |
| ... |
Call-site of Helper
Pretty straightforward. Call-site simply just has the business logic.
More Diagnostic Information
Adding more contextual information besides the stack trace itself could be helpful in making investigation easier, especially with limit diagnostic information reported in production. CoroutineName is one of contextual information that could turn out valuable. But for some reason, I feel like CoroutineName is another element of the context that seemed to be less publicized to developers. So I’d like spend a little extra time covering its nature here.
CoroutineName, Inherited & Overwritten
In business layers(UseCase or Repository), many operations are asynchronous with coroutines. CoroutineName would make a good “Identifier” for those coroutines.
CoroutineName is one of the Elements in CoroutineContext. By default, the parent builders(launch, async/await) passes its context to its children coroutines. While the child inherits the context from its parents, it can also overwrite the elements in it. The following snippet demonstrates this behavior:
| fun CoroutineScope.logWithName(msg: String) { // log message with CoroutineName | |
| val coroutineName = coroutineContext[CoroutineName]?.name | |
| println("[$coroutineName] $msg") | |
| } | |
| fun main() = runBlocking(CoroutineName("main")) { | |
| logWithName("Started") // [main] Started | |
| launch { | |
| delay(300) | |
| logWithName("finished") // [main] finished | |
| } | |
| launch(CoroutineName("launch-101")) { | |
| delay(500) | |
| logWithName("finished") // [launch-101] finished | |
| } | |
| val value = async(CoroutineName("async-202")) { | |
| delay(1000) | |
| logWithName("finished") // [async-202] finished | |
| 888 | |
| } | |
| logWithName("Got ${value.await()}") // [main] Got 888 | |
| } |
Demo Name Inheritance & Overwriting
- CoroutineScope.logWithName(): Helper to log messages with coroutineName as messages’ prefix
- fun main() :
– Launch root-coroutine with name “main”
– “main” coroutine started(launch) a child with no name specification
– “main” coroutine started(launch) a child coroutine named “launch-101”
– “main” coroutine also started another coroutine(async) named “async-202”
If you run main(), you can tell from the result how CoroutineName is inherited and overwritten by child coroutines:
[main] Started
[main] finished // child coroutine with inherited name finished after 300ms
[launch-101] finished // child coroutine named “launch-101” finished after 500ms
[async-202] finished // child coroutine named “async-202” finished after 1s
[main] Got 888 // root coroutine
With this knowledge in mind, you probably want to give a name to your specific child coroutine as an argument to the coroutine builder, so that information could help identify the problematic area when logging to Crashlytics. For example:
| viewModelScope.launch(CoroutineName("GetFavorites")) { | |
| postsRepository.observeFavorites().collect { favorites -> | |
| viewModelState.update { it.copy(favorites = favorites) } | |
| } | |
| } | |
| // or within your custom coroutine scope | |
| launch(CoroutineName("GetFavorites")) { | |
| postsRepository.observeFavorites().collect { favorites -> | |
| viewModelState.update { it.copy(favorites = favorites) } | |
| } | |
| } |
Add Coroutine Names
StackTrace
we can leverage the extension Throwable.stackTraceToString() to populate the error stack trace in the log. So the previous code snippet would look like this with Timber log:
| internal suspend inline fun <T> getResult(block: () -> T): Result<T> = try { | |
| block().let { Result.success(it) } | |
| } catch (e: Exception) { | |
| if (e is CancellationException) throw e | |
| Timber.e("Error from coroutine (${coroutineContext[CoroutineName]?.name}): " + | |
| "${e.stackTraceToString()}") | |
| Result.failure(e) | |
| } |
Add StackTrace
Now when exceptions occur, error log would include both coroutineNameand stackTrace.
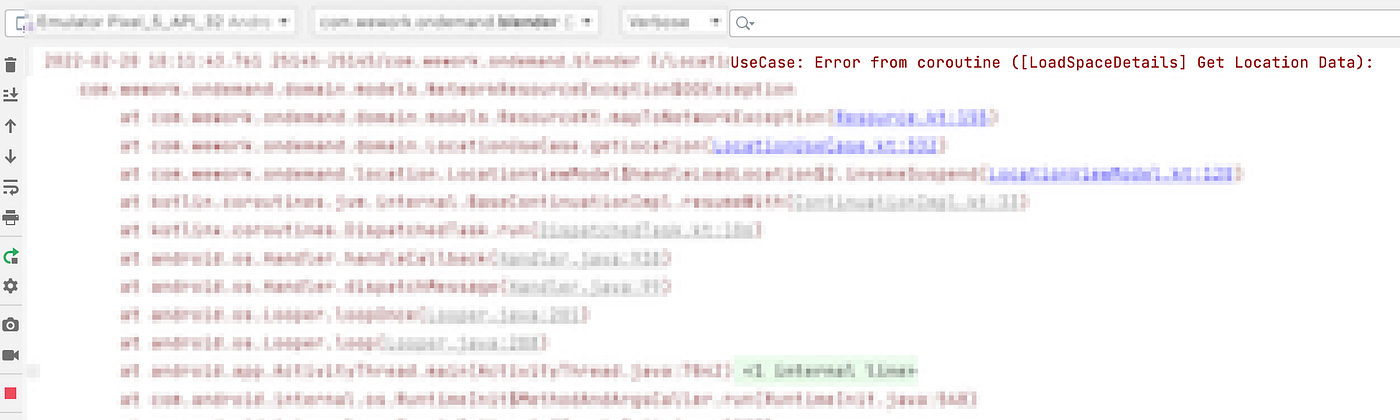 Error Log in Console
Error Log in Console
More Helper Function Examples
In the similar fashion, we can define other helper functions for other patterns in business-logic layer. For example, define a central place to handle coroutine Flows:
| inline fun <T> Flow<T>.catchLog(default: T? = null): Flow<T> = this.catch { e -> | |
| if (e is CancellationException) throw e | |
| Timber.e( | |
| e, | |
| "Error from flow (${coroutineContext[CoroutineName]?.name}): " + | |
| "${e.stackTraceToString()}" | |
| ) | |
| default?.let { emit(it) } | |
| } | |
| // call-site | |
| runBlocking { | |
| flow { | |
| emit(1) | |
| throw RuntimeException("unexpected") | |
| emit(2) | |
| } | |
| .catchLog(default = 0) | |
| .collect { println(it) } | |
| } | |
| // result: | |
| 1 | |
| Error from flow (name): [stacktrace] | |
| 0 // default in case of error |
Helper function for Coroutine Flow
Same idea, a helper function to run Apollo GraphQL queries:
| import com.apollographql.apollo.api.Response | |
| internal suspend inline fun <S> runApolloRequest(block: () -> Response<S>): Result<S> = try { | |
| val value = handleApolloRequest{(block()} | |
| Result.success(value) | |
| } catch (e: Exception) { | |
| if (e is CancellationException) throw e | |
| Timber.e("Exception from coroutine (${coroutineContext[CoroutineName]?.name}): " + | |
| "${e.stackTraceToString()}") | |
| Result.failure(e) | |
| } | |
| // call-site | |
| val priceResult = runApolloRequest { apolloAPI.getPrice(id) } |
Helper Function for Apollo GQL Queries
3. Transparent Logging to Firebase
As many already knew, we can log custom reports to Firebase Crashlytics as non-fatal errors with the following:
Firebase.crashlytics.recordException(e)
The problem is: even with the helper functions that abstract the try / catch / logging ceremony for many cases, there are still places that are not applicable to common helper patterns so they handle exceptions on one-off basis. It would be tedious and easy-to-miss to cover everywhere for the Crashlytics reporting in places of catching exceptions. These is a simpler solution to that: we can customize the Logging configuration so it can continue to log to the system consoles for the debug build but reporting to Crashlytics for the release build transparently. For example, we use Timberfor logging and define the following only in /release resource folder.
| class CrashlyticsReportTree : Timber.Tree() { | |
| override fun log(priority: Int, tag: String?, message: String, t: Throwable?) { | |
| if (priority == Log.ERROR) { // only for error level | |
| with(Firebase.crashlytics) { | |
| // optional: setCustomKey("CUSTOME_TAG", any) | |
| recordException(it) | |
| } | |
| } | |
| } | |
| } | |
| // Configure in Application() when app starts | |
| Timber.plant(CrashlyticsReportTree()) |
Timber Configuration to Firebase in Release Build
Now we can log with Timber.e() as usual in exception handling. And thanks to the custom configuration, Timber would behave differently according to the build flavors transparently:
- Debug build: log errors to the system consoles
- Release build: report to Crashlytics as non-fatal errors
No more random crashlytics.recordException(e) are needed in other places now.
End
Hope you find some of the practice useful to improve the exception handling and the application observability .
For us, this stage of the work was to reduce app crashes and improve the heuristics to address non-fatal errors. The groundwork would enable us to monitor and fix errors based on priorities in the next stage. Happy coding and learning 🙂
Thanks to Nat Pan.
This article was originally published on proandroiddev.com on March 02, 2022







