

Demonstrating how small changes in the code can speed up functions by 15–20%

Introduction
I conducted a small research on measuring the performance of sequences. In this research, I compared the speed of transforming collections using sequences to traditional methods of collection transformation. Throughout the study, I noticed that some sequence functions were slower than they could be.
I proposed optimizations for these functions, and JetBrains accepted my suggestions and has already included them in Kotlin 2.0. (Issue with my optimizations of sequences)
I talk in detail about this research and how each sequence functions work in my article Measuring sequences.
Here, I want to talk only about optimizations and demonstrate how small changes in the code can speed up functions by 15–20%. I want to highlight the importance of understanding the nuances of Kotlin bytecode generation and how it affects the performance of functions.
Optimization distinct
I noticed that the implementation of the distinct function is algorithmically very similar to the filter function. However, the distinct function has a significant performance loss compared to regular collections (-15%), while the filter function outperforms collections by about 3%-5%.
Measurement results — distinct
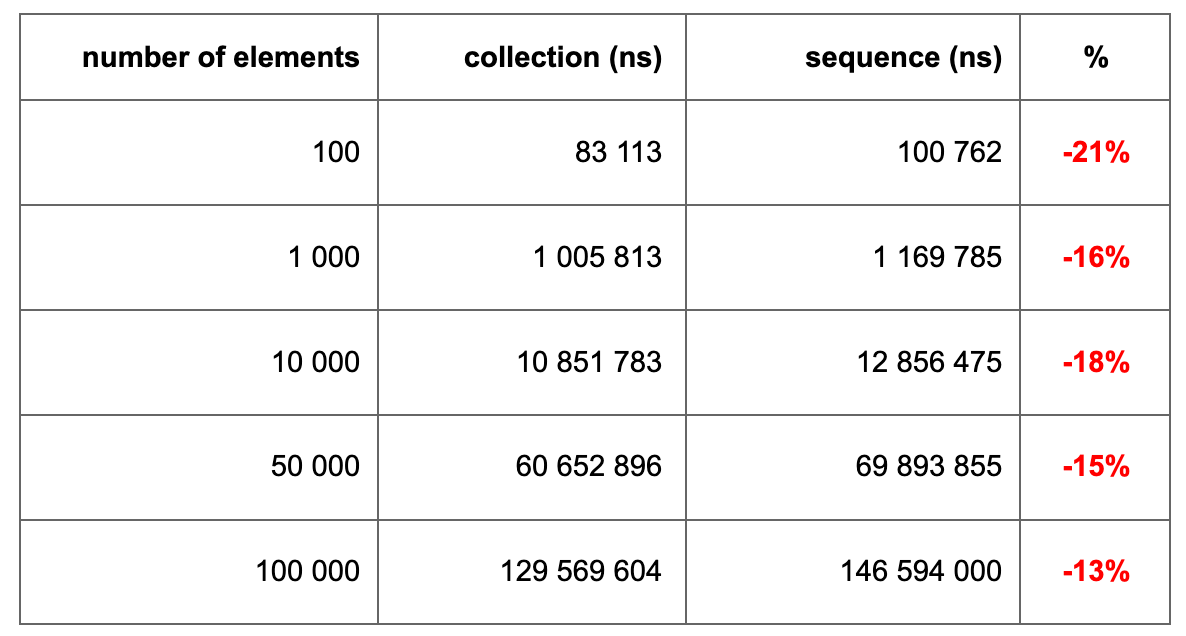
Measurement results — filter
This seemed strange to me and I decided to study the code of both functions to understand why such losses occur in the distinct function.
Implementation of distinct
The decorator for distinct is quite simple. Internally, it creates a HashSet observed and accumulates all the returned elements in it. Thus, if the element is already observed, then this means that it has already been returned and will be skipped further.
private class DistinctIterator<T, K>(
private val source: Iterator<T>,
private val keySelector: (T) -> K
) : AbstractIterator<T>() {
private val observed = HashSet<K>()
override fun computeNext() {
while (source.hasNext()) {
val next = source.next()
val key = keySelector(next)
if (observed.add(key)) {
setNext(next)
return
}
}
done()
}
}
If we look at the implementation of the collections code, we will see almost identical code in the collections. Essentially, it does the same thing. Creates a HashSet and accumulates the returned elements in it.
public inline fun <T, K> Iterable<T>.distinctBy(
selector: (T) -> K
): List<T> {
val set = HashSet<K>()
val list = ArrayList<T>()
for (e in this) {
val key = selector(e)
if (set.add(key))
list.add(e)
}
return list
}
Thus, it is clear that if the implementation of sequences and collections as a whole is the same, then the losses are somewhere else. If we look at the class declaration in sequences, we will see some kind of abstract class AbstractIterator.
private class DistinctIterator<T, K>(
private val source: Iterator<T>,
private val keySelector: (T) -> K
) : AbstractIterator<T>() {
// ....
}
Here is the implementation of all the basic methods of the distinct decorator. And if we follow the logic, then all our losses should be in this abstract class.
Implementation of AbstractIterator
Let’s see how this abstract class works. This class stores the current state in the state variable, whether the next element of the iterator was calculated or not. If it has not yet been calculated, then it calls the tryToComputeNext() function, which calculates the next element.
private enum class State {
Ready,
NotReady,
Done,
Failed
}
public abstract class AbstractIterator<T> : Iterator<T> {
private var state = State.NotReady
private var nextValue: T? = null
override fun hasNext(): Boolean {
require(state != State.Failed)
return when (state) {
State.Done -> false
State.Ready -> true
else -> tryToComputeNext()
}
}
override fun next(): T {
if (!hasNext()) throw NoSuchElementException()
state = State.NotReady
@Suppress("UNCHECKED_CAST")
return nextValue as T
}
private fun tryToComputeNext(): Boolean {
state = State.Failed
computeNext()
return state == State.Ready
}
abstract protected fun computeNext(): Unit
protected fun setNext(value: T): Unit {
nextValue = value
state = State.Ready
}
protected fun done() {
state = State.Done
}
}
It seems that the code is written very competently and at first glance there should be no problems here. But where are our loss then?
The sequence decorator for the filter function is implemented in a very similar way, however, it does not provide such a disadvantage compared to collections. I started comparing the code of the two decorators and looking for significant differences.
Implementation of filter
As you can see, the principle of implementing the filter is very similar. Again, there is a state for calculating the next element and it is also stored in the nextState field.
There is also a method for calculating the next element calcNext(), which is similar to the tryToComputeNext() method in the distinct function
OUR VIDEO RECOMMENDATION




Jobs
internal class FilteringSequence<T>(
private val sequence: Sequence<T>,
private val sendWhen: Boolean = true,
private val predicate: (T) -> Boolean
) : Sequence<T> {
override fun iterator(): Iterator<T> = object : Iterator<T> {
val iterator = sequence.iterator()
// -1 for unknown, 0 for done, 1 for continue
var nextState: Int = -1
var nextItem: T? = null
private fun calcNext() {
while (iterator.hasNext()) {
val item = iterator.next()
if (predicate(item) == sendWhen) {
nextItem = item
nextState = 1
return
}
}
nextState = 0
}
override fun next(): T {
if (nextState == -1)
calcNext()
if (nextState == 0)
throw NoSuchElementException()
val result = nextItem
nextItem = null
nextState = -1
@Suppress("UNCHECKED_CAST")
return result as T
}
override fun hasNext(): Boolean {
if (nextState == -1)
calcNext()
return nextState == 1
}
}
}
It seems that, except for minor implementation details, the two functions are very similar in how they work.
So where is the loss of the distinct function?
At first, due to my incompetence, I suspected the abstract class and the virtual method calls. But no, if you remove the abstract class and move everything into one general class, the function will not be faster.
The only other significant difference between these two functions is Enum.
In the filter function we store the state as a regular Int number
// -1 for unknown, 0 for done, 1 for continue var nextState: Int = -1
And in the case of distinct we use a typed Enum for this
private enum class State {
Ready,
NotReady,
Done,
Failed
}
private var state = State.NotReady
But how can using the Enum class cause a 15% performance loss? This is impossible.
But I didn’t see any other options from the code analysis, so I decided to go down one level and analyze the byte-code of both functions.
If we look at the byte-code of checking the nextState variable for the filter function, we will not see anything unnecessary there. Simply loading variables onto the stack, checking their values, and passing control to call the appropriate block of code.
But if we look at the byte-code of the state variable check in the distinct function, we will see something interesting.
This is the code for checking state variable in the distinct function
return when (state) {
State.Done -> false
State.Ready -> true
else -> tryToComputeNext()
}
byte-code that corresponds to it
#2 L0 #3 LINENUMBER 20 L0 #4 ALOAD 0 #5 GETFIELD AbstractIterator.state : Lcom/AbstractIterator$State; #6 GETSTATIC AbstractIterator$WhenMappings.$EnumSwitchMapping$0 : [I #7 SWAP #8 INVOKEVIRTUAL AbstractIterator$State.ordinal ()I #9 IALOAD #10 L1 #11 TABLESWITCH #12 1: L2 #13 2: L3 #14 default: L4 #15 L2
I don’t think many people know how to read byte-code (at least I couldn’t), so I’m going to explain what’s going on what’s happening here line by line.
#5 — loads a pointer to the state variable onto the local stack
#6 — loads an array of ordinal values of the enum class onto the local stack. (Why?)
#7 — swaps these two variables on the local stack
#8 — gets the ordinal value of the state variable
#9 — IALOAD looks in the array of ordinal values enum class index ordinal values of the state variable (WTF???)
#11 — the found index is passed to the input of the TABLESWITCH operator and then the transition occurs along the required code branch.
As a result, it turns out that when using the when operator in combination with enum, we get an unnecessary loading of the array of all enum values onto the local stack at each comparison.
At the same time, if we rewrite the comparison through ordinal values, we can avoid this unnecessary and costly operation.
return when (state.ordinal) {
State.Done.ordinal -> false
State.Ready.ordinal -> true
else -> tryToComputeNext()
}
In fact, such a check of the enum value by searching the ordinal array of class enum values can only be relevant in one case. When the value checking code can be compiled separately from the enum class declaration code. It seems that this is not possible in the case of Android.
Later, after I understood the problem, I found an old article by Jake Wharton in which he describes a similar problem (R8 Optimization: Enum Switch Maps, 2019)
In this article, he promised to fix this back in 2019, but apparently did not have time.
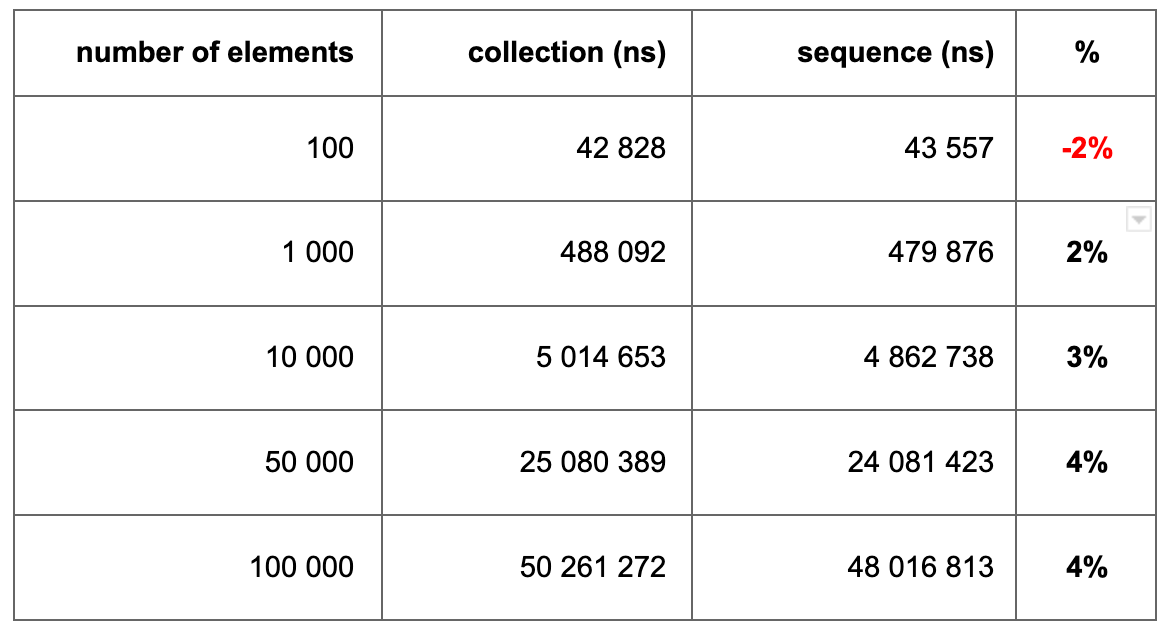
Optimization results for distinct
I tried to rewrite the distinct function taking into account the nuances of enum processing. I removed the enum class and used regular Int constants to store the state.
Measurement results of the original and optimized distinct function
As a result, the function became about 10%-15% faster, which I think is significant.
Source code of the optimized distinct function
private class OptimizedDistinctIterator<T, K>(
private val source: Iterator<T>,
private val keySelector: (T) -> K
) : Iterator<T>{
private val observed = HashSet<K>()
// { UNDEFINED_STATE, HAS_NEXT_ITEM, HAS_FINISHED }
private var nextState: Int = UNDEFINED_STATE
private var nextItem: T? = null
override fun hasNext(): Boolean {
if (nextState == UNDEFINED_STATE)
calcNext()
return nextState == HAS_NEXT_ITEM
}
override fun next(): T {
if (nextState == UNDEFINED_STATE)
calcNext()
if (nextState == HAS_FINISHED)
throw NoSuchElementException()
nextState = UNDEFINED_STATE
return nextItem as T
}
private fun calcNext() {
while (source.hasNext()) {
val next = source.next()
val key = keySelector(next)
if (observed.add(key)) {
nextItem = next
nextState = HAS_NEXT_ITEM // found next item
return
}
}
nextState = HAS_FINISHED // end of iterator
}
}
Optimization flatten
When I did my research, I found that the flatten function outperforms collections by almost 2х times. This function allows you to expand a list of lists into one large, linear list. This is used quite often in various data transformations.
Measurement results of the flatten function
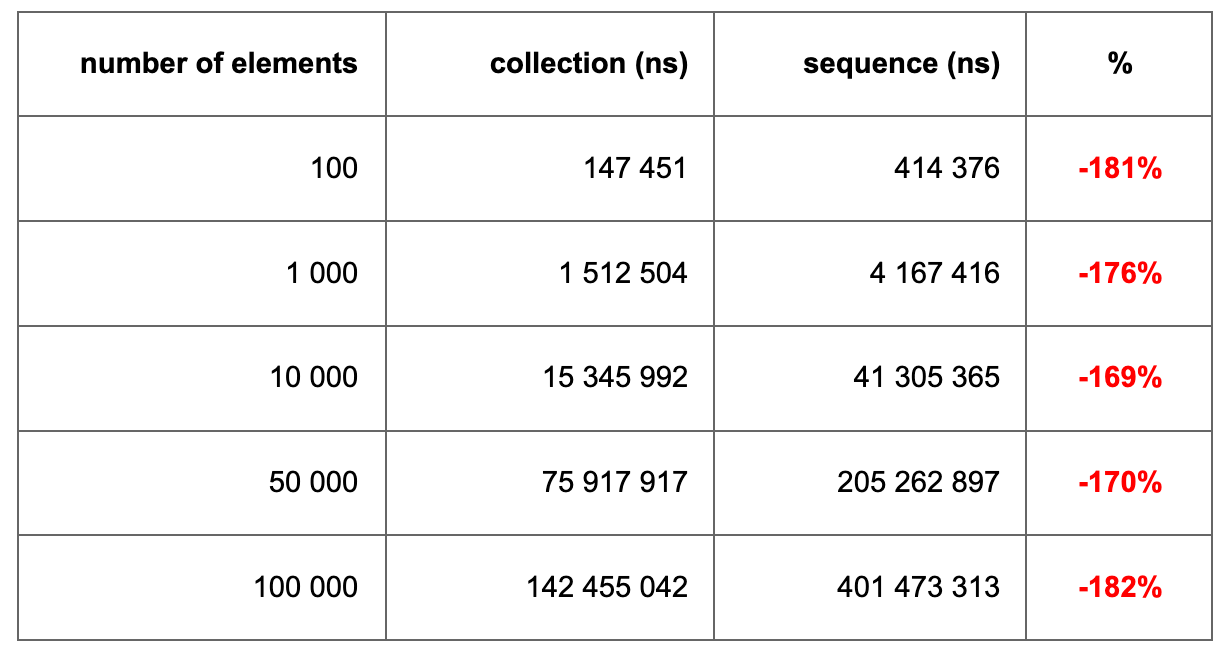
Losing twice is too much. This means we can’t use sequences to transform collections if our transformation contains at least one conversion via flatten operator
What’s even more offensive is that the flatten operator is the basic decorator in sequences and other functions are based on it as well. For example the plus function
public operator fun <T> Sequence<T>.plus(elements: Iterable<T>): Sequence<T> {
return sequenceOf(this, elements.asSequence()).flatten()
}
I wanted to fix this and inspired by the success with distinct optimization, I decided to try optimizing flatten
Implementation of flatten
The decorator for flatten is quite difficult to understand. In general, the principle of its operation is as follows:
For each call to the hasNext() method, the ensureItemIterator() function is called, which calculates the nested list iterator for the current element and writes its value in the itemIterator field.
When the next() method is called, it calls itemIterator.next() and thus all elements are iterated sequentially and the list of lists is expanded into a linear list.
internal class FlatteningSequence<T, R, E>
constructor(
private val sequence: Sequence<T>,
private val transformer: (T) -> R,
private val iterator: (R) -> Iterator<E>
) : Sequence<E> {
override fun iterator(): Iterator<E> = object : Iterator<E> {
val iterator = sequence.iterator()
var itemIterator: Iterator<E>? = null
override fun next(): E {
if (!ensureItemIterator())
throw NoSuchElementException()
return itemIterator!!.next()
}
override fun hasNext(): Boolean {
return ensureItemIterator()
}
private fun ensureItemIterator(): Boolean {
if (itemIterator?.hasNext() == false)
itemIterator = null
while (itemIterator == null) {
if (!iterator.hasNext()) {
return false
} else {
val element = iterator.next()
val nextItemIterator = iterator(transformer(element))
if (nextItemIterator.hasNext()) {
itemIterator = nextItemIterator
return true
}
}
}
return true
}
}
}
At first glance, the class is written in a complicated manner, but if you take a closer look, you realize that it works optimally and there’s nothing special to catch on.
But then I noticed that the itemIterator field is declared as a nullable type
override fun iterator(): Iterator<E> = object : Iterator<E> {
val iterator = sequence.iterator()
var itemIterator: Iterator<E>? = null
This means that when accessing this field, kotlin will each time add a check to ensure that the field value is not Null. And this is an additional read operation.
I marked in the code with asterisks all the places where we have an extra check for Null value.
override fun next(): E {
if (!ensureItemIterator())
throw NoSuchElementException()
** return itemIterator!!.next()
}
private fun ensureItemIterator(): Boolean {
** if (itemIterator?.hasNext() == false)
itemIterator = null
I fixed this by creating an EmptyIterator singleton that implements the logic that ItemIterator should have in case of a Null value.
// Empty iterator for cause when we haven't next element
private object EmptyIterator: Iterator<Nothing> {
override fun hasNext(): Boolean = false
override fun next(): Nothing = throw NoSuchElementException()
}
This allowed me to remove all Null checks when accessing the itemIterator field
override fun iterator(): Iterator<E> = object : Iterator<E> {
val iterator = sequence.iterator()
var itemIterator: Iterator<E> = EmptyIterator
override fun next(): E {
if (!ensureItemIterator())
throw NoSuchElementException()
return itemIterator.next() // was itemIterator!!.next()
}
private fun ensureItemIterator(): Boolean {
if (itemIterator.hasNext() == false) // was itemIterator?.hasNext()
itemIterator = null
Then I noticed that every time next() and hasNext() are called, the fairly complex ensureItemIterator() function is always called.
override fun next(): E {
if (!ensureItemIterator())
throw NoSuchElementException()
return itemIterator.next()
}
override fun hasNext(): Boolean {
return ensureItemIterator()
}
Since we always work with iterators using the hasNext() + next() method pair, it seems wasteful to call the ensureItemIterator() function twice to process each element. Its result can easily be cached in a field that stores the state of its calculation.
I added a state field and set it every time ensureItemIterator() is evaluated, and reset it when the next() method is called.
Thus, the ensureItemIterator() function is now called only once per pair of hasNext() + next() calls.
All this allowed me to significantly optimize the execution time of the flatten function.
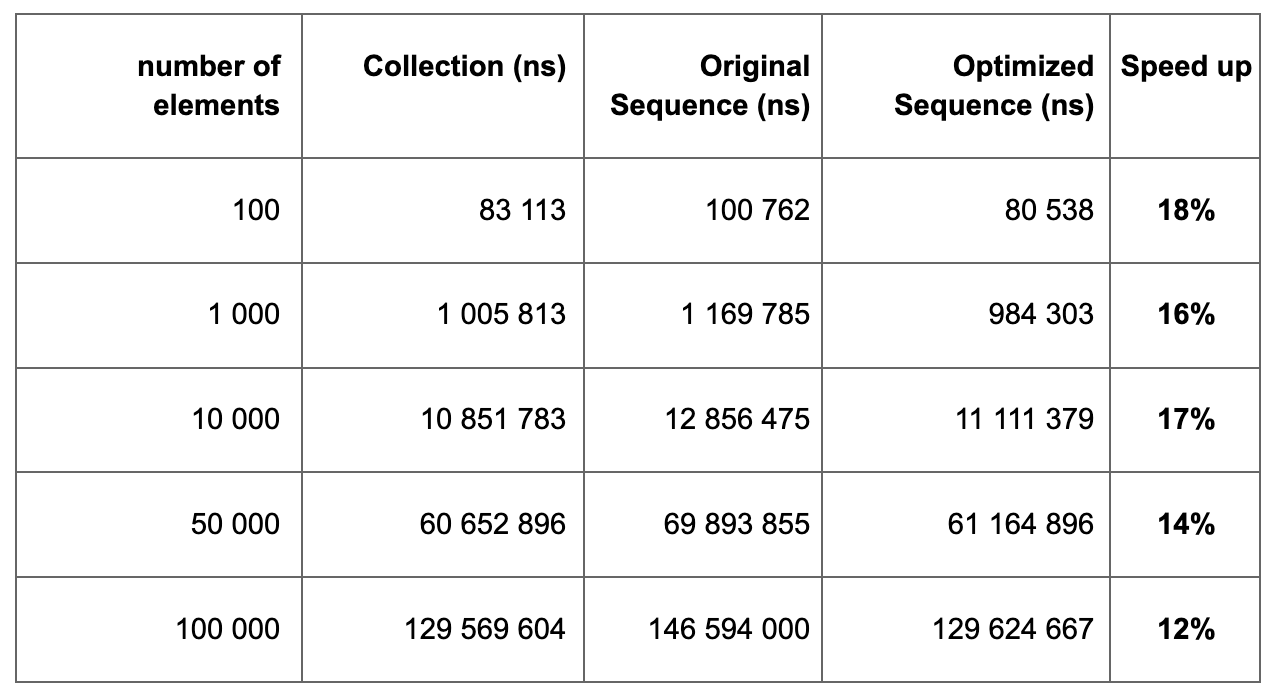
Optimization results for flatten
Removing the nullable variable and introducing a calculation state for ensureItemIterator significantly sped up the function. The gain is 35%-37%, which in my opinion is quite significant.
Measurement results of the original and optimized flatten function
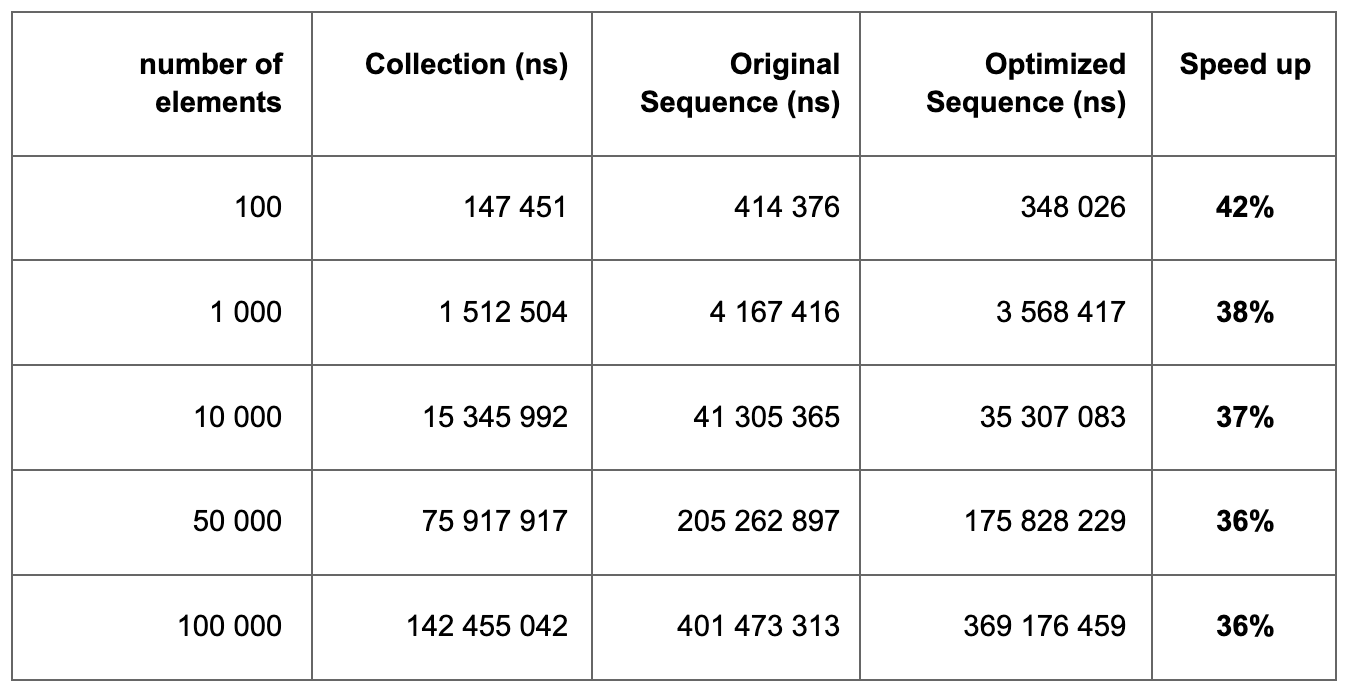
Source code of the optimized flatten function
// Empty iterator for cause when we haven't next element
private object EmptyIterator: Iterator<Nothing> {
override fun hasNext(): Boolean = false
override fun next(): Nothing = throw NoSuchElementException()
}
internal class FlatteningSequence<T, R, E>
constructor(
private val sequence: Sequence<T>,
private val transformer: (T) -> R,
private val iterator: (R) -> Iterator<E>
) : Sequence<E> {
override fun iterator(): Iterator<E> = object : Iterator<E> {
private val iterator = sequence.iterator()
private var itemIterator: Iterator<E> = EmptyIterator
// { UNDEFINED_STATE, HAS_NEXT_ITEM, HAS_FINISHED }
private var state: Int = UNDEFINED_STATE
override fun next(): E {
if (state == UNDEFINED_STATE) {
ensureItemIterator()
}
state = UNDEFINED_STATE
return itemIterator.next()
}
override fun hasNext(): Boolean {
return when (state) {
HAS_NEXT_ITEM -> true
HAS_FINISHED -> false
else -> ensureItemIterator()
}
}
private fun ensureItemIterator(): Boolean {
if (itemIterator.hasNext()) {
state = HAS_NEXT_ITEM
return true
} else {
while (iterator.hasNext()) {
val nextItemIterator = iterator(transformer(iterator.next()))
if (nextItemIterator.hasNext()) {
itemIterator = nextItemIterator
state = HAS_NEXT_ITEM
return true
}
}
state = HAS_FINISHED
itemIterator = EmptyIterator
return false
}
}
}
}
Submitting optimizations to JetBrains
At first I was afraid that communicating my suggestions for optimizing sequences would be a difficult and painful process. Still, JetBrains is a global company and it was difficult for me to imagine that they might be interested in my proposals. But everything turned out to be much simpler than I thought.
JetBrains has an open youtrack where anyone can create their own Issue and describe a problem or suggestion. I created my own issue with optimization suggestions and after 4 months it was already merged into the main branch of kotlin 2.0.
And now a part of me, my ideas, is in global kotlin…
If you find a problem or see some good solution, then don’t be afraid to create an Issue in global products.
These products are made by people just like you, and it’s possible that you came up with a brilliant idea that will help make the product better.
This article was previously published on proandroiddev.com







