


In the clean world of Kotlin coroutines, we can have many tasks running at different times, stacked up into surprisingly few threads. These coroutines often have to talk to one another, for example when an asynchronous task has finished and needs to report back, or an ongoing task needs to deliver results.
Kotlin has a number of different constructs to help us manage this communication. Suspend functions are helpful for waiting on asynchronous tasks, and flows are required if we’re expecting multiple results.
 This article lifts the lid on asynchrony in general, and introduces flows in particular. We’ll discover why flows are needed, the difference between hot and cold flows, and how to turn callbacks into suspend functions and flows.
This article lifts the lid on asynchrony in general, and introduces flows in particular. We’ll discover why flows are needed, the difference between hot and cold flows, and how to turn callbacks into suspend functions and flows.
To illustrate these recipes I’ve used examples from Firestore, which is a cloud database service in which records are called “documents”. That’s literally all you need to know about Firestore here.
Recipe 1: Java callbacks, the bad old days
To begin with, here’s something that is neither a suspend function nor a flow. Here’s how we get a document from Firestore:
Firebase.firestore.collection("users").document("me")
.get() // Start the asynchronous download of the "me" document
.addOnSuccessListener { result ->
// This function will be called the download completes
}
This is an asynchronous callback pattern. You request something; it does the work asynchronously and comes back later on with the result.
APIs written for backward compatibility with Java are full of asynchronous callbacks like this. Consider this pattern deprecated: it’s not very Kotlin-y.
Recipe 2: Doing callbacks the Kotlin way: suspendCoroutine
A better way of handling the above situation — where you request something and get the result later — is using suspending functions, which leverage the power of Kotlin coroutines. My last blog post explained suspending functions in depth, but the summary is: they suspend the current coroutine without blocking the thread they’re running on.
The good news is that you can turn a callback into a suspend function*. The function you need is suspendCoroutine:
suspend fun getDocument() = suspendCoroutine { continuation ->
Firebase.firestore.collection("users").document("me")
.get()
.addOnSuccessListener { result ->
//Resumes the suspended coroutine with the document we've received
continuation.resume(result)
}
}
Great. So now you can call getDocument() much more simply, for example in a ViewModel:
viewModelScope.launch(Dispatchers.IO) {
val location = getDocument()
}
See how Kotlin has removed all of Java’s boilerplate baggage, and we can just call the function using a single line? Beautiful.
Anti-recipe 1: Suspend functions can only return once
But what if we are expecting more than one response?
Firestore can be asked to keep us updated with new versions of the document whenever anyone changes it. We use addOnSnapshotListener for that, and Firestore calls our listener whenever there’s an update:
Firebase.firestore.collection("users").document("me")
.addOnSnapshotListener { snapshot, error ->
// This function will be called whenever the "me" document is updated.
}
Can we turn this into a suspend function? No! Suspend functions only return once. Calling continuation.resume() more than once causes an IllegalStateException (“Already resumed”):
So we need something different. What we need is a flow.
Recipe 3: Using callbackFlow to return multiple things from an async callback
A Kotlin flow is a conveyor belt of data. Someone loads objects onto one end of the conveyor belt, and someone else handles them at the other end.
When an object hits the flow’s conveyor belt, we say it’s been emitted by the flow. When it gets taken off the conveyor belt to be handled, we say it’s been collected by a collector.
For our Firestore example, we need to create a flow onto which document data is loaded. Later we will write code to collect it.
Turning a multi-shot callback into a flow: callbackFlow
Here we create a flow “conveyor belt” and load the updated document onto it. The updated document is represented by the snapshot we get from the callback:
// Create the flow "conveyor belt" using callbackFlow:
val documentFlow = callbackFlow {
// Ask Firestore to keep us updated on changes to the "me" document
database.collection("users").document("me")
.addOnSnapshotListener { snapshot, error ->
// Load the updated document onto the "conveyor belt" of this flow:
trySend(snapshot)
}
}
This creates a flow object which emits every snapshot received from Firestore.
Recipe 4: Collecting a flow
So now we’ve set up this conveyor belt, which we’ve assigned to a variable called documentFlow. How do we get the results?
Answer: we collect them using the collect function:
viewModelScope.launch {
documentFlow.collect { snapshot ->
// This is the snapshot placed on the conveyor belt earlier
}
}
This function suspends, so it needs to go in a coroutine. The lambda we pass to collect is called whenever a new item appears on the conveyor belt.
Let’s consider the lifecycle of this a bit. The collect function will suspend until the conveyor belt stops running.
How can a flow conveyor belt stop running? There are only two ways:
- By closing: the emitter has nothing more to give, so it calls close() to request that the conveyor belt stops.
- By error: the emitter throws an exception. This automatically closes the flow.
Of course, neither of the above conditions may ever be hit, so the conveyor may never stop running. The collect call could therefore represent an endless loop. However the genius of coroutines means that the collect function is cancellable, so in the above example, collection will stop as soon as the viewModelScope is cancelled. And so the code above is actually perfectly safe. More in my blog post on coroutine scope, context and Jobs.
Recipe 5: Cold flows and awaitClose
The code in the callbackFlow lambda runs as soon as a collector starts collecting. Each new collector will cause the code to run again, even if it’s running in parallel with another collector. This is known as a cold flow behaviour.
Because of this, we need to make sure that we shut down the Firestore connection when the collector stops collecting. We can do this automatically using awaitClose { }:
val documentFlow = callbackFlow {
val listener = database.collection("users").document("me")
.addOnSnapshotListener { snapshot, error ->
...
}
// The awaitClose block runs whenever the collector stops collecting
awaitClose {
// Shut down the connection to Firestore
listener.remove()
}
}
The awaitClose { } block runs whenever the collector stops collecting. We use it to unregister our listener to the remote database.
Notice how we haven’t had to make any changes to our higher-layer code: we still call documentFlow.collect { … } as per recipe 4 to collect this flow. Nothing else is needed to guarantee that everything gets shut down as required at the end.
Recipe 6: SharedFlow and multiple collectors
Remember, the code in the callbackFlow lambda runs as soon as a collector starts collecting. That means that if we have a hundred simultaneous collectors, we’ll be opening up a hundred connections to Firestore**. Not very efficient when we could make do with one.
What we really want is a flow that can take multiple collectors. It must start up the Firestore connection when the first collector starts collecting, and shut it down when the last one stops. And any other collector which arrives in between those times, should just receive copies of the data without opening new Firestore connections.
In other words, we want to (somewhat) decouple the continuing emissions of the flow from the arrival/disappearance of any individual collector. So we don’t want a cold flow any more, we want a hot flow. The collectors of a hot flow are called subscribers — the slight change in language is to emphasise the fact that the flow continues independently of the subscriber. The subscriber is just “checking in”, not driving it.
The specific kind of hot flow we need here is a SharedFlow. A SharedFlow exists to broadcast data to multiple subscribers. For example here’s a coroutine which loads data onto a SharedFlow conveyor belt:
OUR VIDEO RECOMMENDATION




Jobs
| val sharedFlow = MutableSharedFlow<Int>() | |
| viewModelScope.launch { | |
| var count = 0 | |
| // Every 500ms, emit a new number in sequence | |
| while (true) { | |
| delay(500) | |
| sharedFlow.emit(count++) | |
| } | |
| } |
So long as that coroutine is running, data is moving down the conveyor belt. It doesn’t matter if anything is collecting it or not.
If we subscribed at the exact moment the flow started flowing, we’d see 0, 1, 2, 3, 4 …. But if we start collecting it a few seconds later:
| viewModelScope.launch { | |
| // Time passing before we start collecting... | |
| delay(4000) | |
| // Start collecting the flow | |
| sharedFlow.collect { | |
| println(it) | |
| } | |
| } | |
| // Output: 7, 8, 9, 10, ... |
…it misses the first few emissions and outputs 7, 8, 9, 10, 11…. That demonstrates that the flow had started flowing before we’d started collecting.
Recipe 7: Sharing a cold flow, making it hot
shareIn() is designed to take a cold flow and turn it hot. That is, it will launch a coroutine to collect the cold flow, and re-broadcast anything it gets to its subscribers. It could have any number of subscribers, including zero.
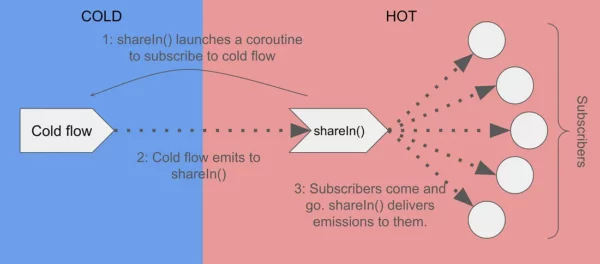
Here’s shareIn()’s function definition:
fun <T> Flow<T>.shareIn(
scope: CoroutineScope,
started: SharingStarted,
replay: Int = 0
): SharedFlow<T>
What scope will the coroutine be launched into? That’s the scope parameter.
When will the coroutine be launched? That behaviour is controlled by the started parameter. It could be:
SharingStarted.Eagerly: the coroutine starts immediately, and only ends when cancelled (usually by the scope being cancelled).SharingStarted.Lazily: the coroutine starts when the first subscriber comes along, and ends when cancelled.SharingStarted.WhileSubscribed(stopTimeoutMillis = X): the coroutine starts when the first subscriber comes along, and stops X milliseconds after the last subscriber leaves. Having X > 0 is useful if it’s resource-intensive to set up the stream (e.g. it involves an outbound connection) and you know it’s likely that that subscribers will come back shortyly after disappearing.
An Android Activity is an example of where you’d use SharingStarted.WhileSubscribed() with a stopTimeoutMillis of, say, 5000 ms. Activities are killed and restarted when the device rotates, so subscribers will disappear for a few milliseconds during that process. To prevent shutting down and immediately restarting the cold flow, shareIn’s coroutine will stick around for 5000 ms.
Finally, you can use the replay parameter to cause subscribers to receive current and previous values when they first subscribe.
To summarise…
- You can turn an asynchronous single-shot callback into a suspend function using suspendCoroutine.
- If you have a multiple-shot callback, you need a flow. You can turn a multiple-shot callback into a flow using callbackFlow.
- Cold flows, like those generated from callbackFlow, run separately for each collector.
- Hot flows run independently of their collectors (which are known as subscribers).
- An example of a hot flow is a SharedFlow, which exists to broadcast emissions to multiple subscribers. You can turn a cold flow into a SharedFlow using sharedIn().
I hope this has been helpful. All comments welcome!
Asynchrony in Kotlin is a very wide topic. And flows in particular have a lot going on. I intend to write some more articles laser-targeted at particular sub-topics of these, so please do let me know in the comments or on LinkedIn what might be most helpful.
* To all the Firestore fans who will point out that I could just use await() from the kotlinx-coroutines-play-services library to turn this particular callback into a suspended operation. Yes, obviously you are right. But then you wouldn’t get this nice example would you? 🙃
** Firebase is actually more intelligent than that and will avoid opening up multiple connections. See above.
Tom Colvin is a Google Developer Expert in Android, and has been architecting software for two decades. He’s co-founder and CTO of Apptaura, the mobile app specialists, and available on a consultancy basis.
This article is previously published on proandroiddev.com







