

In this article, I will tell you about the Branch by Abstraction technique. Being a well-known approach in software engineering, it is still not that common in mobile development. I will describe it from an Android developer’s perspective, but it is all true for almost any project and platform.
The story
Imagine you are finishing up the refactoring you’ve been doing for the last two weeks. You’ve done a good job on it, and now you’re finally making a pull request, and … 12 conflicts.
Or you are merging your changes into the main branch frequently, your code is up to date. You make another pull request, it hangs for a couple of days, then you get approved, and … 15 conflicts. Someone has merged their big pull request before you.
But you did everything right. You were working on refactoring in a separate thread. Why do you have to solve these conflicts, and is there a simpler way to do that? Is it possible to work in some special branch, which can be easily merged into the main one without conflicts? Well, turns out you can.
I’m going to describe the Branch by Abstraction technique — the way it can help to avoid accumulating large changes in your branch, prevent merge hell, and pump your CI.
I will give examples from Android development but they are also true for most types of projects and platforms.
Are there different types of branches?
Let’s start with the first word — Branch. Usually, we associate the word branch with a branch in a version control system (like Git). When starting a new task, the first thing we do is:
git checkout -b feature/new-feature
and we know that we’ve just created a new branch.
But let’s think of a branch in a more general way, not exactly the Git branch — rather as an abstract branch of code.
How can we make an abstract branch? There are different ways.
- Copy a file. Let’s say we have
New File.txt. We make a copyCopy of New File.txt. Great! We’ve just created a new version of the code, a new branch. - Make-files configuration can create different versions of the code.
- Even use
ifoperator in the code. Great!if-elsecan create two versions of the code.
Keep on and come up with other ways.
All these examples are as trivial as possible but they demonstrate the way to think about an abstract branch of code.
As you may have guessed, Branch by Abstraction is a technique where we create a branch of code through an abstraction.

Do I really need it?
When should I use Branch by Abstraction? For every feature, or what?
In terms of the development process, Branch by Abstraction is a tool. It can be useful in one case and unnecessary in another.
You probably don’t want to use it when:
- The task is small. There are just a few changes, and the pull request is small. It is unlikely you will have problems merging changes into the main branch;
- You are making an application by yourself. More likely you will do the tasks sequentially, and won’t have a situation where you change the same code in different branches on your own;
- The project is well divided into isolated modules, and all teams can work independently from each other.
On the contrary, these are the situations where Branch by Abstraction can help a lot:
- Large and long-going refactoring or a feature in the common code;
- Your branch in the repository is out of date. It is common for us to postpone half-done tasks as we get distracted by new ones.
So what is Branch by Abstraction?
Paul Hammant is one of the main evangelists on the Branch by Abstraction (one of the first articles on the subject). You can explore his numerous materials on the Internet. There is also a more compact version by Martin Fowler. Personally, I like the description Martin gave:
“Branch by Abstraction” is a technique for making a large-scale change to a software system in gradual way that allows you to release the system regularly while the change is still in-progress.
Simply put, Branch by Abstraction is a development technique that implies that you do a task gradually and release the application at the same time.
Like any technique, Branch by Abstraction relies on a set of rules. There are 5 steps (some glue them up to 4).
- Introduce an abstraction.
- Create a new implementation.
- Turn on for yourself, turn off for others.
- Work on the new implementation step by step.
- Remove the old implementation.
Each of the steps is described in detail in the following sections.
I will use the well-known names of classes in Android. But in general, it is not tied to the platform in any way and can be applied anywhere.
Task
Let’s say we have a MenuRepository class that uses MenuDataSource data source as a dependency. It’s a super-standard situation (especially for Android developers). It looks something like this:
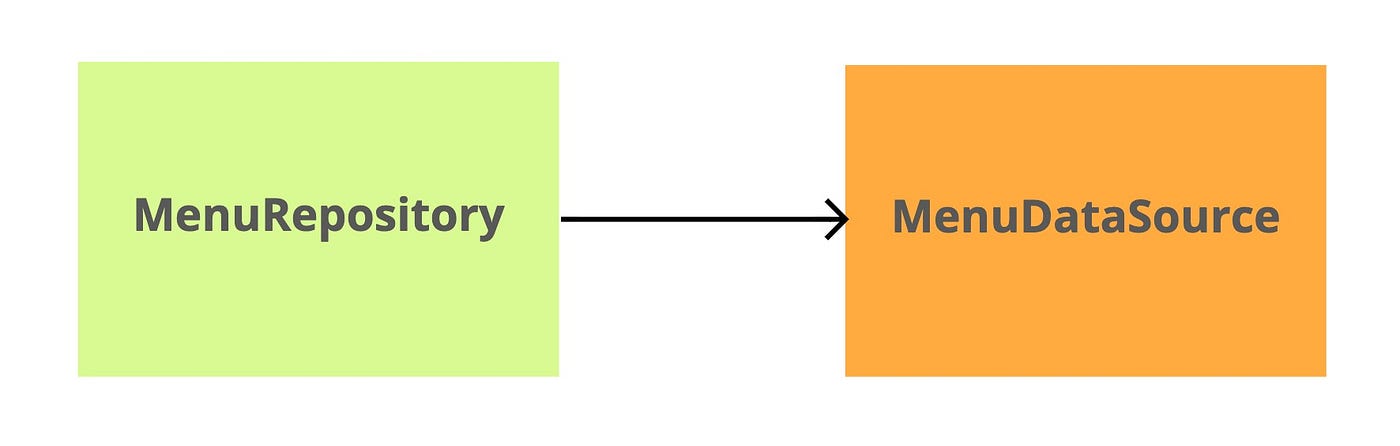
Our task is to refactor ManuDataSource or create a new implementation of the data source.
— –
Step 1: Introduce an abstraction
The first thing we need to do is introduce an abstraction. For example, we introduce the MenuDataSource interface and take the implementation to MenuDataSourceImpl.

☝ In general, an abstraction can be introduced anyhow: through composition, inheritance, or functional abstraction. In the examples, I will use composition as the most common way.
This small change can be, and should be, immediately merged into the main branch—it is safe and does not affect the work and the MenuRepositorycode.
Step 2: Create a new implementation
You can start by making a no-op implementation or a copy of an existing one. In the diagram, I named it NewMenuDataSourceImpl.

Jobs
It also can be immediately merged into the main branch. The only thing to keep in mind is that if you’re making a copy of an existing implementation, you’d better copy all the tests along with it. Yes, there will be some duplicated code, but this is a temporary solution while you’re working on the new implementation. The tests should also be edited and updated in the process.
Step 3. Turn on for yourself, turn off for others
Now you need to make sure that you can work on the new implementation, while other developers will work on the old one by default. If your project already has toggles, better use them. If not, you can do it any way you want. Most importantly—verify that the abstraction will be turned off and that there is no way to enable it at runtime. For example, if you have a toggle mechanism that your backend sends you, then you need to have guarantees that it can’t enable your abstraction on production.
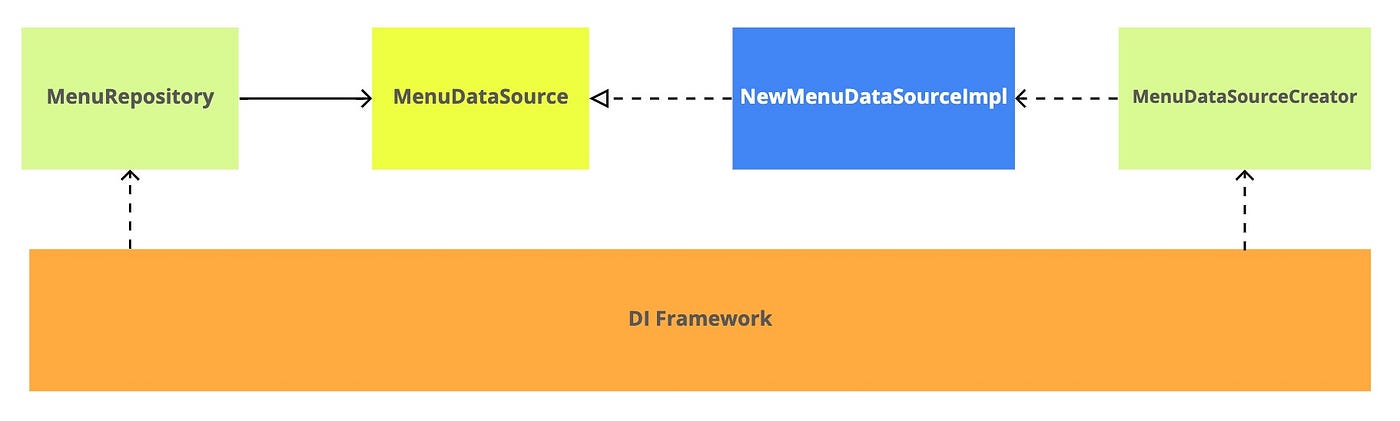
I’ve added a MenuDataSourceFactory factory that knows how to produce the desired DataSource. Let’s imagine that toggle logic is encapsulated there.

I’ve added a DI Framework to the diagram as an example of how MenuRepository can get the correct implementation of DataSource.
Now you can merge all changes into the main branch again. Congratulations! From this point on, we can consider that we’ve created an abstract branch, the very Branch by Abstraction.
Step 4: Work on the new implementation step by step
At the 2020 Branch By Abstraction talk, Paul Hammant gives a pie chart of Branch by Abstraction work.
He says that once you’ve introduced an abstraction, you can work in the abstract branch in small iterative steps: making a new implementation, refactoring, and writing tests. The main thing to track is that the project has been built successfully and all tests are passed, i.e. that there is a green pipeline in your CI.
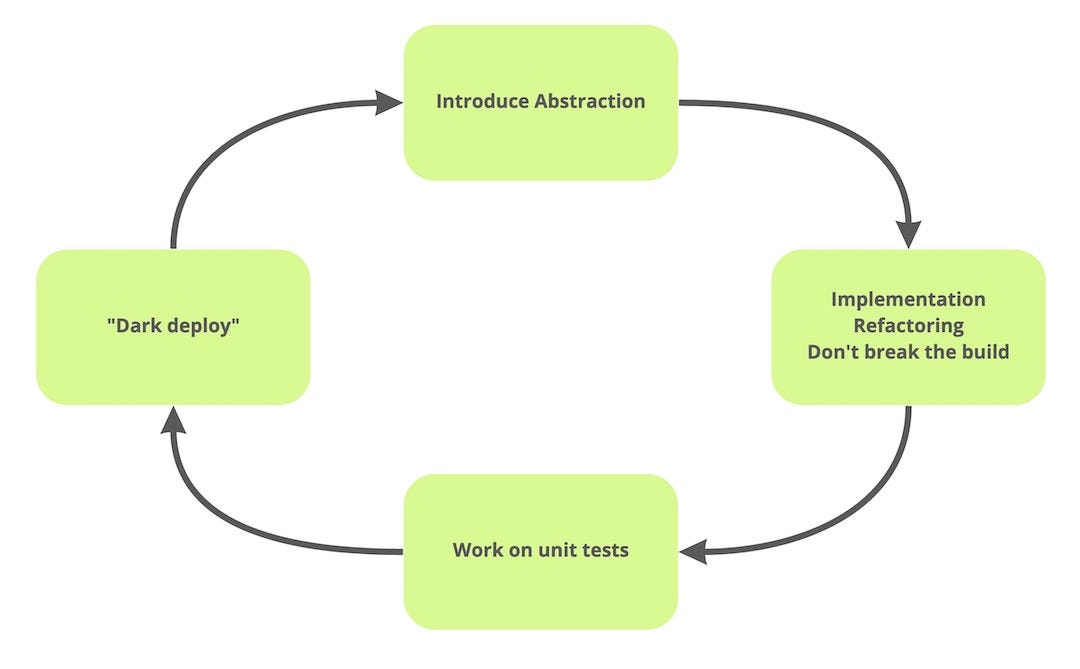
By integrating changes often and in small chunks, you will avoid large merges, and your colleagues will see changes in the code faster. If they happen to have a task nearby, they will see what you have going on. And you will be able to discuss it with them as early as possible.
This step usually is the biggest one: once you’ve created an abstract branch, you can work on it for weeks or even months.
Step 5: Remove the old implementation
Once you’re done with the new implementation, the old one can be removed along with the enabling mechanism (i.e., delete toggles).
That is, it will end up looking like this.
If necessary, you can remove abstractions as well. In my opinion, this is an unnecessary step, unless you are approaching that famous saying (a joke about the Fundamental theorem of software engineering):
We can solve any problem by introducing an extra level of indirection… except for the problem of too many levels of indirection
But if you delete everything, it becomes quite simple:
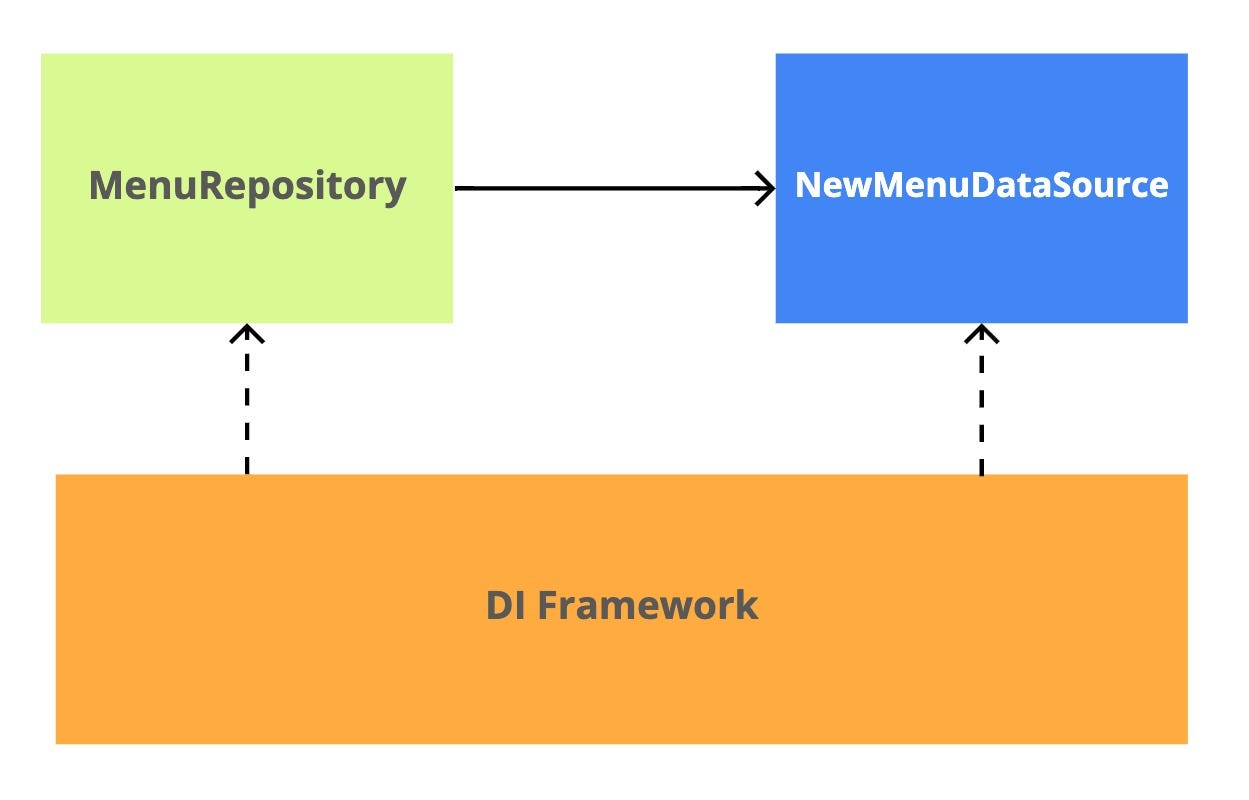
“Wait! I saw all those left-to-right arrows while reading about dependency inversion! Is that the same thing?” — you might ask. No, it’s not the same thing.
It is not the Dependency Inversion
Indeed, everything that I drew you can find in articles and books about Dependency Inversion (that letter D of SOLID). Looks very similar — introduce the interface, draw the right arrow, and voila.
Here we need to understand an important and fundamental difference. When we talk about dependency inversion, the key idea is how modules or layers depend on each other. Whether the direction of dependencies changes if we introduce an abstraction. Far from always, introducing an abstraction will change the dependency between modules or layers. The figure below shows the difference.
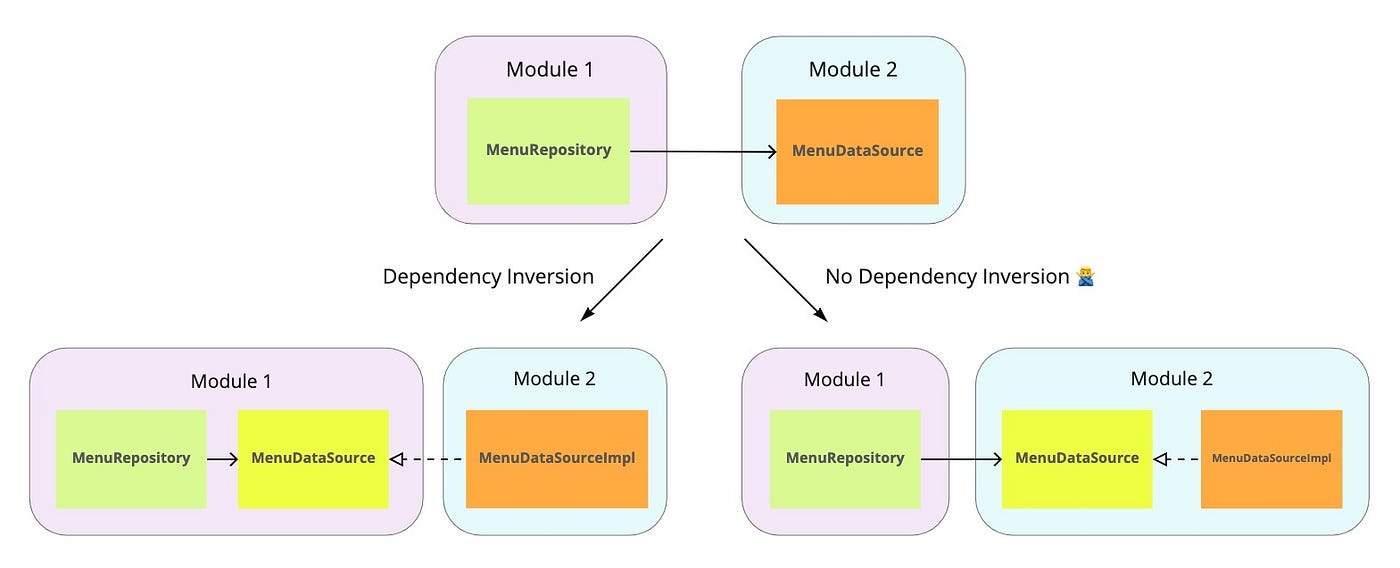
On the left, it is the dependency inversion. Module 1 depends on Module 2, then we invert this, and now Module 2 depends on Module 1.
On the right, it’s not a dependency inversion. Module 1 depends on Module 2 both before the changes and after them.
Dependency inversion is about the way dependencies are organized in an application. It helps, for example, to separate business logic from application logic or infrastructure.
Branch by Abstraction is a technique that allows creating of a virtual branch of code and working within it. It has nothing to do with organizing dependencies in an application.
Additional benefits
Before I finish, I’d like to list the extra perks we get with Branch by Abstraction.

Easy to pause
Branch by Abstraction is most suitable for large and long tasks, for long refactoring or moving from one framework to another. But we live in such a fast-changing world that tomorrow you’ll rush to do another task. With Branch by Abstraction, I can easily pause the task. And I don’t keep a separate branch for a long time and constantly update it.
The releases don’t stop
It is critical for businesses to release new features and releases regularly and predictably. It’s also important for development teams because small and regular releases increase the system’s stability. The lower the frequency of releases, the greater the chance of releasing an unstable build and heroically rushing to fix it.
Branch by Abstraction allows shipping the code that doesn’t work yet. The only thing to ensure is that it compiles and is securely hidden by a toggle.
The code gets better
Many of us have (or will soon have) legacy code. Or just some code that is not written perfectly or according to the architectural conventions of the team. Often such code is not even covered by tests. In this case, introducing an abstraction will also lead to improved testability of the code. If you introduce an abstraction, there’s a better chance to cover the new implementation with tests with no rush and avoid missing something because of a merge hell. I don’t mean there should be an abstraction for every sneeze. But for legacy code and code with high coupling, introducing abstractions that can be tested is likely to be beneficial.
Conclusion
Let’s summarize. Can you do a large-scale and long refactoring and not suffer from merge conflicts afterward? Yes, you can, — Branch by Abstraction is just right for that!
This technique allows you to work on long tasks, while regularly (even daily) merging your code into the main branch.
The basic idea is that we are working in an abstraction branch, not in a Git branch. We create it ourselves in the code by introducing an abstraction and the toggle mechanism.
Branch by Abstraction consists of 5 simple steps which are super easy to follow.
The main thing to remember is that the code can be shipped into production at any time. So it has to be covered by tests, have a green pipeline, and there should be no possibility of accidentally turning it on in production.
I hope this article was useful and that you can now apply this technique to your project. If you’re already using it, drop a comment — I’d love to read about your experience.
Also, I would like to share some code examples for Branch by Abstraction in Part 2. Please let me know if you are interested in it!
This article was originally published on proandroiddev.com on September 05, 2022





